


Yapay Zeka İçin Yapılandırılmış Veri: Schema ile AI Görünürlüğünü Desteklemek İçin İpuçları
Son dönemde dijital pazarlama ve SEO dünyasında ortak bir soru öne çıkıyor: AI platformlarında ne kadar görünüyoruz? Markalar artık yalnızca Google sonuçlarında kaçıncı sırada olduklarını değil; yapay zeka destekli arama motorları, chatbot ve AI yanıt sistemleri tarafından nasıl algılandıklarını ve ne ölçüde referans alındıklarını sorguluyor. Her ne kadar bu alanda ölçümleme ve standartlar hâlâ netleşmemiş olsa da, bazı teknik kriterlerin AI açısından belirleyici olduğu artık açık. Bunların başında ise, içeriklerin ve markaların AI sistemleri tarafından doğru şekilde anlaşılmasını sağlayan yapılandırılmış veriler geliyor. Blog yazımda yapılandırılmış veri kullanımının AI görünürlüğü üzerindeki etkisine değinecek ve alınabilecek başlıca aksiyonları özetleyeceğim.
Yapılandırılmış Veri (Schema) Nedir?
Yapılandırılmış veri (schema), bir web sayfasında yer alan içeriğin arama motorları tarafından daha doğru ve tutarlı şekilde anlaşılmasını sağlayan standart bir işaretleme yöntemidir. Sayfada yer alan önemli bilgileri arama motorlarına açık ve tanımlı bir biçimde sunar.
Schema.org standartlarına dayanan bu yapı genellikle JSON-LD formatında uygulanır ve ürün, makale, organizasyon, yazar, etkinlik veya SSS gibi içerik türlerinin arama motorları tarafından ayrıştırılabilir ve anlamlandırılabilir veri alanları olarak değerlendirilmesini sağlar. Bu sayede içerik yalnızca metin olarak değil, sınıflandırılmış bir veri yapısı olarak ele alınır.
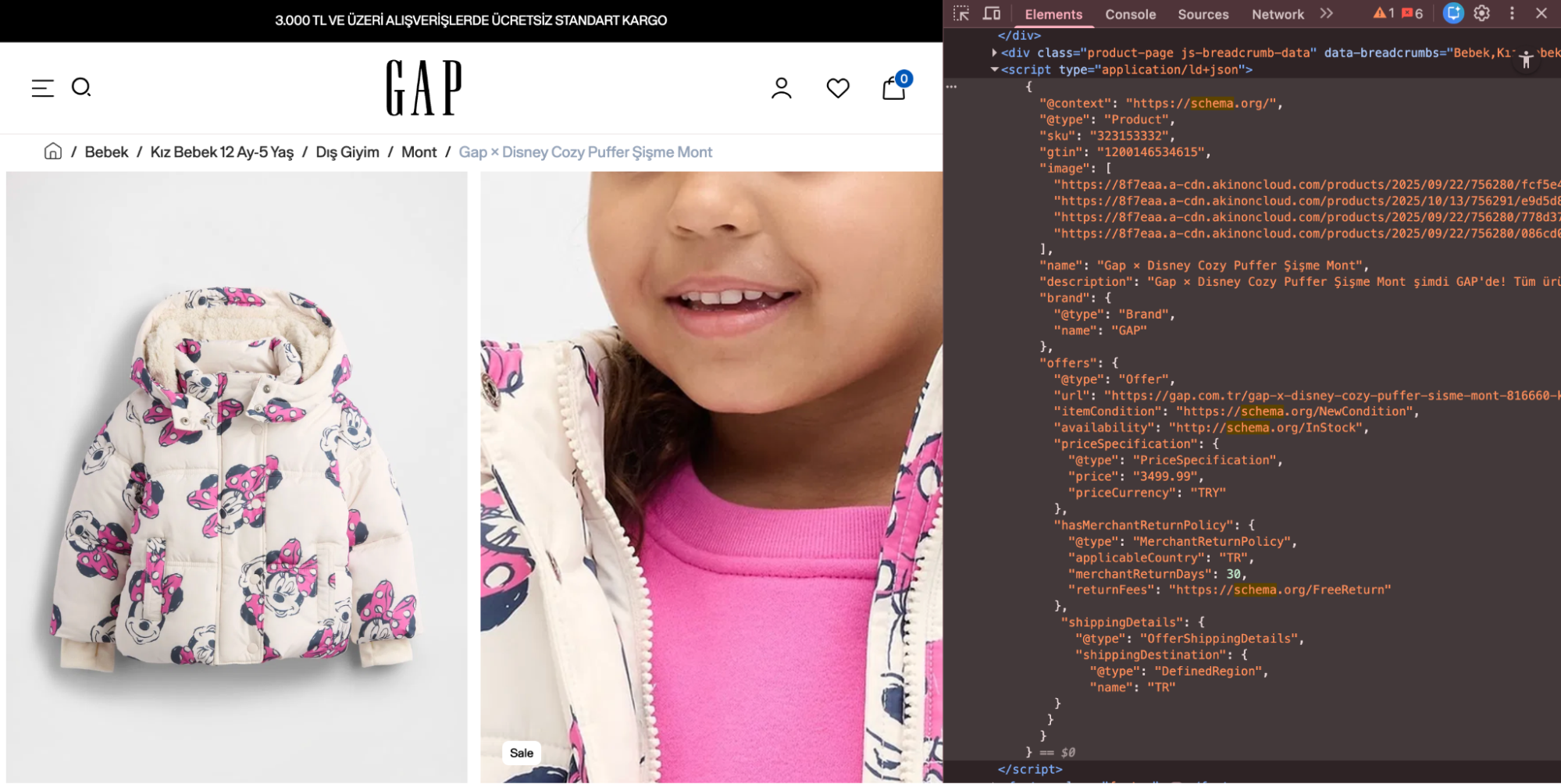
Aşağıda, JSON-LD formatında tanımlanmış Product Schema örneği görebilirsiniz. Schema içerisinde name, description, brand, price gibi elementler ile ürün detayları belirtilmiştir.
Yapay Zeka Sistemleri Yapılandırılmış Veriyi Nasıl Okur?
Yapay zeka sistemleri, geleneksel algoritmalardan farklı olarak veriyi bir bütün halinde değil; parçalara ayrılmış ve anlamsal olarak etiketlenmiş varlıklar üzerinden değerlendirir. Düz metin içerikler, farklı bağlamlarda farklı anlamlar üretebilirken, schema işaretlemeleri içerikteki varlıkların neyi temsil ettiğini net biçimde ortaya koyar. Bu yaklaşım, yapay zeka modellerinin metni anlamlandırma yükünü azaltır; AI gösterimlerini olumlu yönde etkileyebilir ve içeriğin referans alınma olasılığını artırabilir.
Bir yapay zeka modelinin bir kaynağı referans olarak kullanabilmesi için, sunulan bilginin doğruluğundan ve kaynağın otoritesinden emin olması gerekir. Schema işaretlemeleri, key-value yapısı sayesinde bu kesinliği teknik olarak sağlar ve güçlü bağlamsal sinyaller üretir. Yapılandırılmış veri sayesinde içerik daha hızlı sınıflandırılır, diğer varlıklarla doğru şekilde ilişkilendirilir ve tutarlı biçimde yorumlanır. Bu da sayfanın AI sistemleri tarafından daha kolay anlaşılmasını sağlar ve güvenilir bir referans olarak kullanılma potansiyelini güçlendirir.
Aşağıdaki tablo, geleneksel SEO ile yapay zeka odaklı GEO arasındaki yapılandırılmış veri kullanım farklarını özetlemektedir:

Özetle, yapılandırılmış veri artık yalnızca zengin sonuç elde etmeye yönelik bir SEO optimizasyonu değil; yapay zeka sistemleri tarafından anlaşılabilir, doğrulanabilir ve referans alınabilir bir kaynak olmanın temel gerekliliğidir.
Yapılandırılmış Veri Kullanarak AI Görünürlüğü Nasıl Artırılabilir?
1 - Product Schema’da Ürün Özelliklerinin Geliştirilmesi
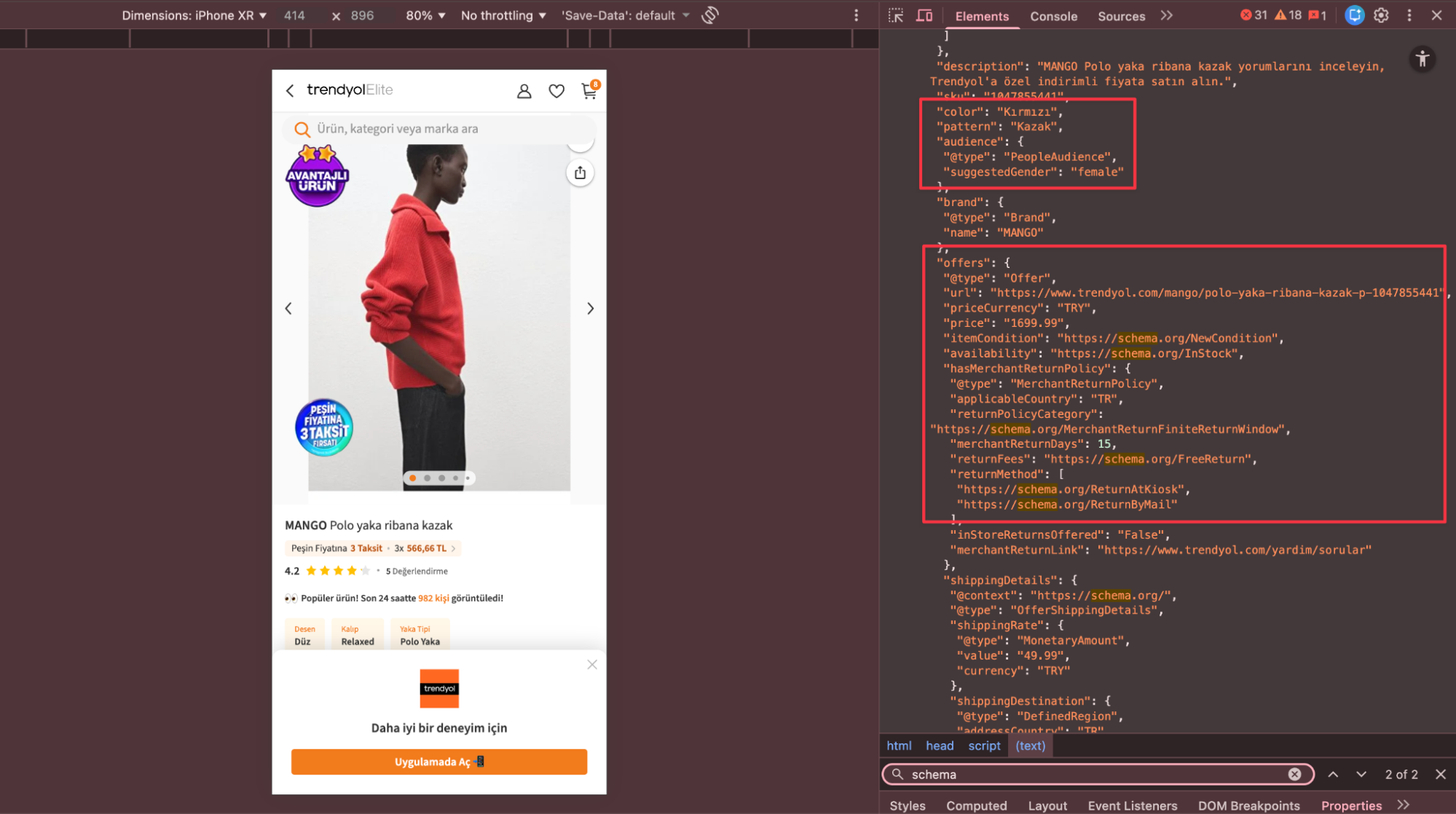
Product schema’da ürün adı, açıklama, fiyat gibi temel alanların işaretlenmesi artık standart bir uygulama olsa da, AI tabanlı arama deneyimlerinde asıl ayırt edici unsur ürün niteliklerinin detay seviyesidir. Kullanıcılar AI destekli aramalarda “kırmızı yün kazak” veya “su geçirmeyen outdoor ayakkabı” gibi son derece spesifik ve niyet odaklı ticari sorgular oluşturabilmektedir. Bu noktada yalnızca name ve price gibi temel alanlarla sınırlı kalan sayfalar yerine; color, material, size, pattern gibi ürünü farklılaştıran özelliklerin schema içerisinde açık ve net şekilde tanımlanması, AI sistemlerinin sayfayı daha doğru anlamlandırmasına ve kullanıcı niyetine uygun sonuçlar üretmesine katkı sağlayacaktır.
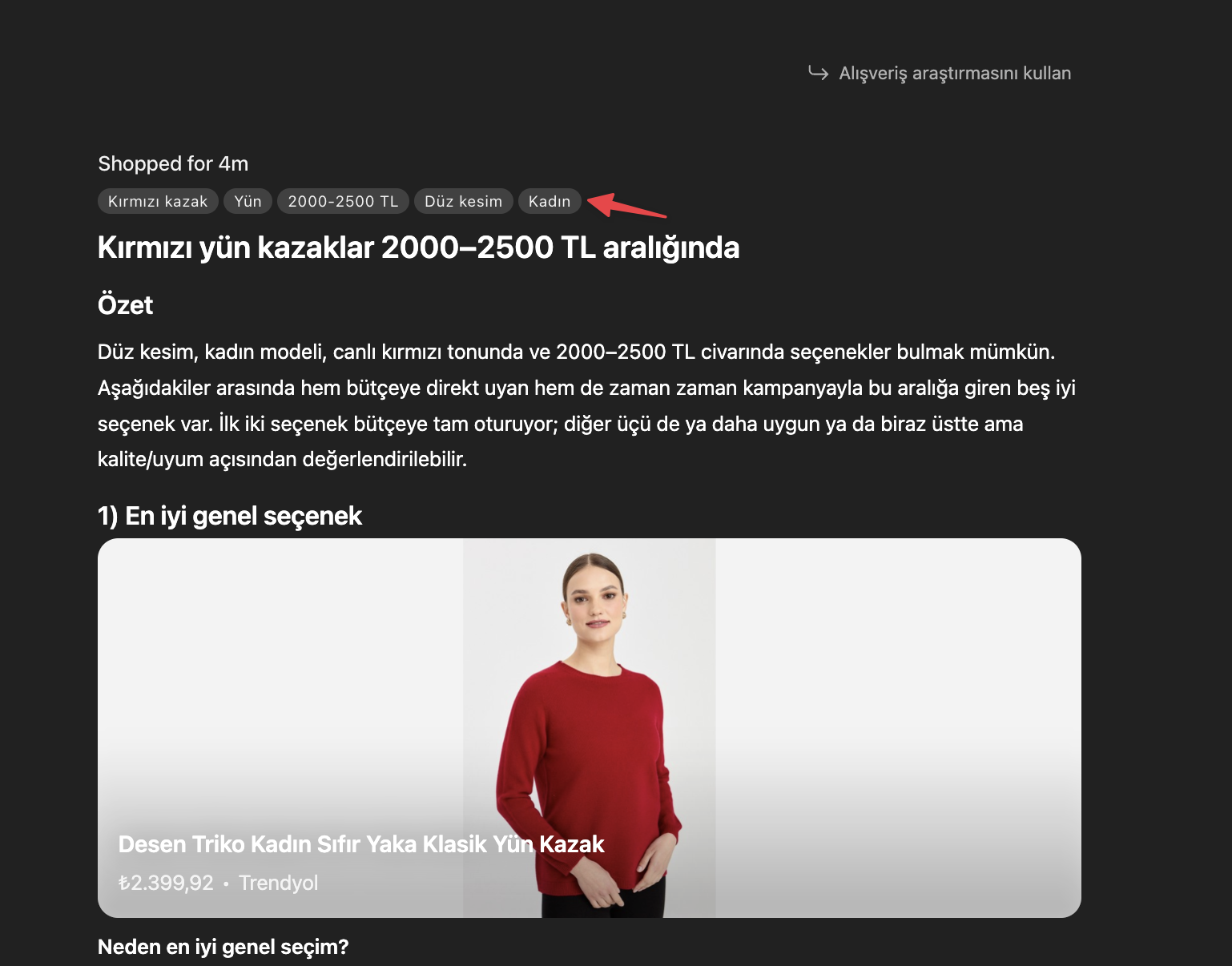
Örneğin, ChatGPT’de kırmızı kazak için alışveriş araması yaptığımızda aşağıdaki gibi materyal, kesim, cinsiyet, fiyat gibi detayların girdi olarak istendiğini görebilirsiniz. Dolayısıyla bu girdileri schema kodları içerisinde sağlamak AI platformlarında referans alınma olasılığını artırabilir.
Materyal bilgilerine ek olarak ticari sorgularda satın alma kararı ve lojistik veriler de oldukça kritiktir. Availability (stok durumu) ve shippingDetails (kargo detayları) gibi bilgilerin schema’da yer alması ürünün satın alınabilir ve ulaşılabilir olduğunun kanıtıdır. Dolayısıyla bu elementlerin mutlaka Product schema içerisinde kullanılması önerilir. Bu alanların eksik olduğu durumlarda, stokta olmayan ya da kargo seçenekleri belirsiz ürünler AI platformlarında geri planda kalabilir veya hiç gösterilmeyebilir.
Aşağıda gelişmiş bir product schema örneği görebilirsiniz.
Ürün attribute’larının kapsamlı şekilde işaretlenmesi doğrudan bir sıralama garantisi sunmasa da, botların ürünü daha isabetli kategorize etmesi için özellikle e-ticaret sitelerinin bu bilgileri sunması kritiktir.
Okumaktan yoruldunuz mu?
Bu blog yazısının, Google NotebookLM ile oluşturulmuş sesli özetini Spotify'dan da dinleyebilirsiniz.
2 - Organization ve Person için E-E-A-T Sinyallerinin Güçlendirilmesi
AI sistemleri bir içeriği değerlendirirken yalnızca ne söylendiğine değil, kimin söylediğine ve hangi otoriteyle söylediğine de odaklanır. E-E-A-T yönergeleri bir noktada AI sistemleri için de geçerlidir diyebiliriz. Dolayısıyla Organization veya Person schema ile dijital kimliği tanımlamak yapay zeka görünürlüğü üzerinde etkili olabilir.
Organization schema’da yalnızca marka adı ve logo bilgisi vermek yerine legalName, url, contactPoint, address, foundingDate, sameAs gibi alanlar doldurulmalı ve marka kimliği AI botlara net bir şekilde sunulmalıdır. Özellikle sameAs alanı; markanın LinkedIn, Google Business Profile, Wikipedia gibi güvenilir üçüncü parti kaynaklarla ilişkilendirilmesini sağlayarak AI sistemleri için güçlü bir doğrulama katmanı oluşturur. Bu bağlantılar, markanın dijital ekosistemde tanımlı bir varlık olduğunu kanıtlar.
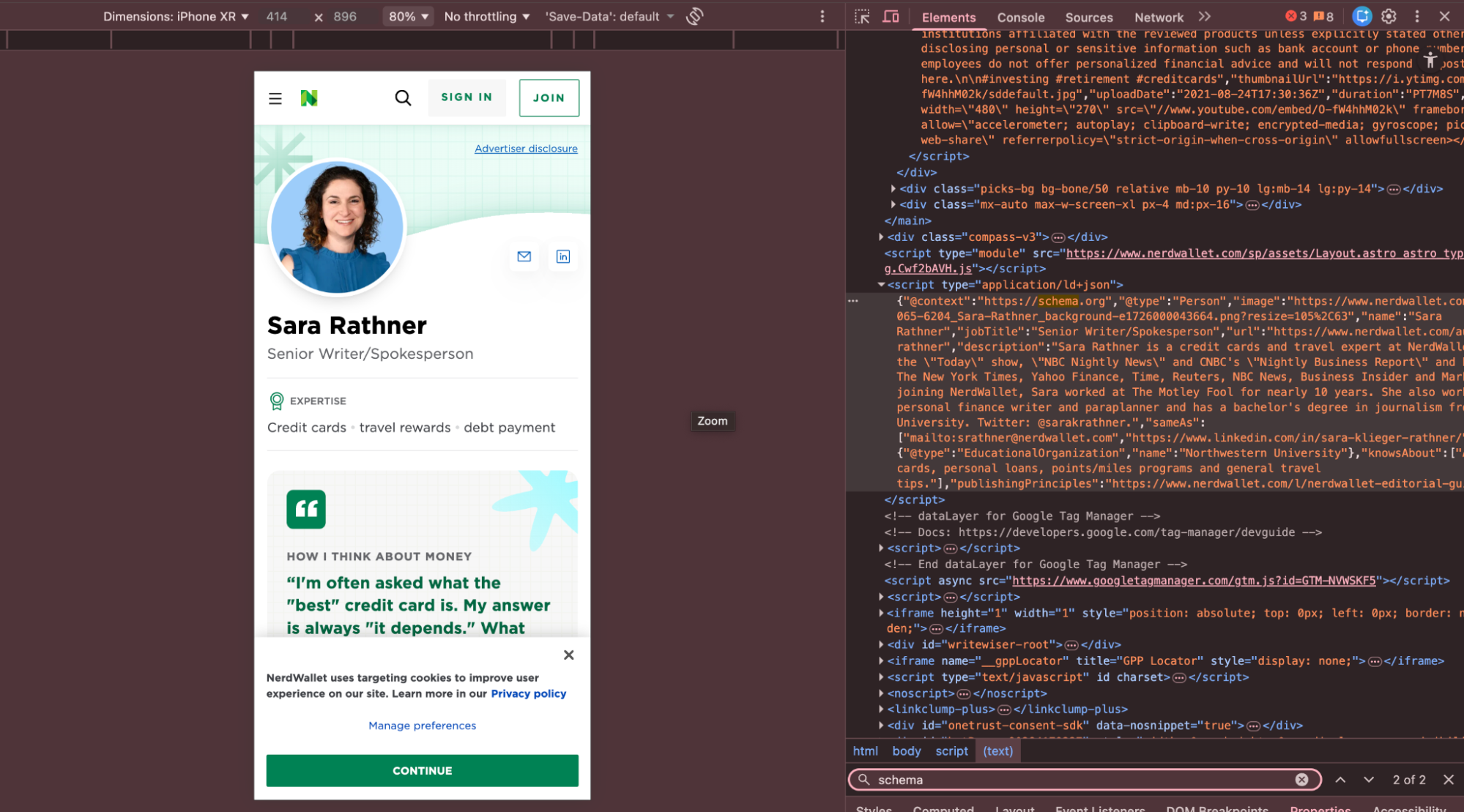
Person schema ise içerik üreticileri, uzman yazarlar ve marka temsilcileri için kritik önemdedir. AI sistemleri anonim veya kimliği belirsiz içerikler yerine, uzmanlığı tanımlanmış kişilere ait içerikleri referans almaya daha yatkındır. Person schema’da name alanının ötesine geçilerek jobTitle, worksFor, knowsAbout, alumniOf, sameAs gibi özelliklerin kullanılması; yazarın hangi konularda yetkin olduğunu ve bu yetkinliğin hangi bağlamda oluştuğunu açıkça ortaya koyar. Bu yapı, özellikle YMYL (Your Money Your Life) kapsamına giren finans, sağlık, hukuk ve ticaret içeriklerinde AI görünürlüğü açısından belirleyici bir fark yaratır.
Aşağıda gelişmiş bir person schema örneği bulabilirsiniz.
3 - FAQ Schema Kullanımı & Soru Optimizasyonu
Google’ın FAQ zengin sonuçlarını kısıtlaması bu işaretlemenin önemini yitirdiği algısını yaratsa da, GEO süreciyle birlikte FAQ Schema kritik bir geri dönüş yaptı. Kullanıcıların yapay zeka platformlarında uzun kuyruklu sorgularla etkileşime girmesi, FAQ schema bloklarını AI sistemleri için en verimli veri kaynaklarından birine dönüştürdü.
Bu süreçte FAQ alanlarını, yalnızca yüksek arama hacmine sahip kelimeler etrafında kurgulamak yerine, kullanıcı niyetini ve muhtemel sorularını daha yakından takip eden bir yaklaşımla ele almak faydalı olabilir. Örneğin mermer ve seramik ürünleri sunan bir markanın, “Mermer nedir?” gibi genel bir soruya odaklanmak yerine; FAQ Schema ile işaretlenmiş “Banyo zemininde mermer mi yoksa seramik mi daha güvenlidir?” sorusuna ve kullanım senaryosuna dayalı net bir cevaba yer vermesi AI sistemleri açısından çok daha değerlidir.
4 - Article Schema’nın Zenginleştirilmesi
Article schema, bir içeriğin ne zaman yayımlandığını, ne zaman güncellendiğini ve kim tarafından üretildiğini arama motorlarına ve AI sistemlerine net biçimde aktaran temel işaretlemelerden biridir. AI platformları referans kaynakları belirlerken güvenilir ve doğrulanabilir içerikleri önceliklendirme eğilimindedir. Bu nedenle E-E-A-T prensipleri gözetilerek hazırlanan ve içerik, yazar ve yayıncı bilgileri schema içerisinde açık şekilde sunulan sayfalar, AI sistemleri tarafından daha kolay anlaşılabilir ve referans alınabilir hale gelir.
Özellikle mevzuat, fiyat veya sağlık gibi hızla değişen konularda datePublished ve dateModified alanlarının güncel olması önemli bir sinyal üretir. Güncellenmiş içeriklerin schema ile işaretlenmesi, AI sistemlerinin en güncel ve geçerli bilgiyi sunma ihtiyacını karşılar ve bu içeriklerin referans alınma olasılığını artırabilir. Benzer şekilde içerik yalnızca author alanı ile sınırlı kalmamalı, yazar için detaylı bir profil sayfası oluşturulmalı ve bu sayfa Person schema ile desteklenmelidir. Yazarın uzmanlık alanı, çalıştığı kurum ve güvenilir üçüncü parti profillerinin işaretlenmesi, yazarın otoritesini güçlendirir ve bu kişiye ait içeriklerin AI platformlarında öne çıkmasına katkı sağlayabilir.
5 - Speakable ve VideoObject Schema Kullanımı
Yapay zeka modelleri artık yalnızca metinleri değil, ses, görüntü ve video gibi farklı veri türlerini de aynı anda işleyebilen bir yapıdadır. Bu gelişim, içeriklerin sadece okunabilir değil, aynı zamanda dinlenebilir ve izlenebilir olduğunun da teknik olarak işaretlenmesini zorunlu kılar. Speakable schema kullanılarak içeriğin en can alıcı kısımlarının sesli asistanlar ve yapay zeka sistemleri tarafından seslendirilebilir olarak tanımlanması, içeriğin sesli arama sonuçlarında ve AI asistan yanıtlarında önceliklendirilmesini sağlayabilir. Bu, özellikle hızlı bilgi tüketimi hedeflenen rehber içeriklerde markanın otoritesini pekiştiren bir sinyaldir.
Videonun yapay zeka stratejisindeki rolü ise VideoObject schema ile çok daha kritik bir boyuta taşınmaktadır. Yapay zeka sistemleri, bir videonun içeriğini analiz ederken vakit kaybetmek yerine, schema içerisindeki hasPart veya key points gibi alanlar üzerinden videonun hangi saniyesinde hangi konunun anlatıldığını doğrudan anlayabilir. Videoların bu şekilde yapılandırılması, yapay zekanın kullanıcıya sunduğu yanıtlarda videonuzun spesifik bir bölümünü doğrudan çözüm olarak referans gösterme ihtimalini artırır. Bu yaklaşım, içeriğinizin sadece bir metin yığını değil, zengin ve erişilebilir bir bilgi kaynağı olarak konumlanmasını sağlar.
6 - Schema–Content Tutarlılığı
Yapılandırılmış verilerin AI sistemleri tarafından güven sinyali olarak algılanması, sayfada görünen içerik ile koddaki verinin birbiriyle örtüşmesine bağlıdır. Yapay zeka modelleri, halüsinasyon riskini en aza indirmek için birden fazla kaynaktan veri doğrulaması yapar. Eğer JSON-LD kodunuzda yer alan bir fiyat, teknik özellik veya yazar bilgisi, sayfanın görünen metninden farklı ise bu durum AI sistemleri için bir çelişki oluşturabilir ve AI görünürlüğünü olumsuz etkileyebilir. Bu yüzden, görünen metin ve schema mutlaka birbirleriyle tutarlı olmalıdır.
7 - Format Tercihi
Yapılandırılmış verileri web sitenize eklemek için Microdata veya RDFa gibi farklı yöntemler bulunsa da, yapay zeka sistemleri ve modern arama motorları için JSON-LD tartışmasız en çok önerilen formattır. Google’ın da resmi olarak desteklediği ve önceliklendirdiği bu format, AI görünürlüğü stratejilerinde teknik bir standart haline gelmiştir.
JSON-LD, HTML kodundan bağımsız, temiz bir veri bloğu sunduğu için yapay zeka botlarının tasarım karmaşasına takılmadan içeriği çok daha hızlı ve hatasız işlemesini sağlayacaktır. Bu yapı, AI modellerinin veriler arasındaki anlamsal bağları kolayca kurmasını sağlayarak markanızın güvenilir bir referans olarak algılanma ihtimalini artırabilir.
Özetle, yapılandırılmış veri artık yalnızca SEO’ya destek olan teknik bir uygulama değil; yapay zeka sistemleri tarafından doğru anlaşılmanın ve güvenilir bir kaynak olarak konumlanmanın temel koşullarından biridir. Ölçümleme araçlarının kısıtlı olması bu alanda net veri sağlanmasının önüne geçse de temiz, anlaşılır kod yapısı googlebot gibi temel arama motoru botlarında olduğu gibi AI botların da web sitesini anlamlandırmasında kolaylık yaratacaktır. Bu yüzden, schema optimizasyonu sağlayabilir ve rakipleriniz adım atmadan AI referans sayılarınızı artırmaya yönelik aksiyon alabilirsiniz.






