


Long-tail Kelimeleri R'da Nasıl Analiz Edebilirsiniz?
R Studio’da long-tail keywords olarak tanımlayabileceğimiz kelimeleri nasıl analiz edebileceğinizi ve sonuçların nasıl aksiyona dönüşebileceğini bu makalemde anlatmaya çalışacağım. Ayrıca hem raporlamalarda hem de sunumlarda daha rahat yorumlamalar için olabildiğince faydalı grafikleri kodlarıyla beraber ekledim. Makalede gösterdiğim tüm veriler kendi blogumda belirli bir tarih aralığında alınmış olup, örneklemim oldukça yüksektir. Analizlerimi sadece exportta yer alan “Query” sekmesi ile yapacağım.
Neden Long-Tail Kelimeleri Önemsemeliyiz?
Long-tail kelimeler, aranma hacimleri az olmasına rağmen hem dönüşüm hem de ziyaretçilerinizin arama amacını anlayarak onlara yardımcı olmanız için size avantaj sağlar. Bu kelimelerin belki yerel düzeyde aranma hacimleri 5000 değil; ama yine de en niche hedef kitleye ulaşmak için long-tail bence kullanabilirsiniz. Ayrıca unutmayın Google AI Overviews sonuçlarda yer almak için planlarınızı şimdiden oluşturabilirsiniz.
R ile Long-tail Kelimelerin Analizi
Analizlerimde API yerine Search Console’dan export aldığım veri setini kullandım. İsterseniz R Studio Search Console API kullanımı yazımda anlattığım şekilde de verileri alabilirsiniz. Export, Excel şeklinde olabileceği gibi .csv’de olabilir bu tamamen sizin tercihinize bağlı. Kodlarda işinizi kolaylaştırmak için zaman zaman yorum satırları da kullandım. Klasik olarak dosyamızı R içine atıyoruz:
library(readxl)
data <- read_excel("Desktop/data.xlsx")
View(data)

İstediğim Search Console verilerim artık hazır. View(data) ile kontrol edebilirsiniz:

Uyarı: Tablodaki sütun başlıklarının ismini değiştirirseniz kod içinde de değiştirmelisiniz, yoksa kodlar çalışmayacaktır. Ayrıca bazı paketler sizde zaten olabilir tekrar yüklemeyebilirsiniz.
R’a benim long-tail kw tanımını yapmam lazım. Bunun için öncesinde her kelimenin uzunluğunu hesaplamak gerekiyor:
library(dplyr)
data <- data %>% mutate(word_count = str_count(Query, "\\w+"))

3 veya daha fazla kelimeden oluşan sorguları "long tail" olarak kategorize edebiliriz: (Siz isterseniz 4’te yapabilirsiniz)
long_tail_data <- data %>% filter(word_count >= 3)

Long tail tanımından sonra en basit olarak long tail kelimelerin click ve impression gibi değerlerinin ortalamasını hesaplayabilirim:
summary_stats <- long_tail_data %>%
summarise(
avg_clicks = mean(Clicks),
avg_impressions = mean(Impressions),
avg_ctr = mean(CTR),
avg_position = mean(Position)
)
print(summary_stats)
Aşağıdaki gibi bir sonuç karşımıza çıktı. Buna göre long tail kelimelerimin ort. Pozisyonu 6.28 iken bu kelimelerim ortalama 11.2 click alıyormuş. Bu kelimelerin medyanlarını vs. bir sürü çıktı daha alabilirim; ama ben biraz daha basit anlatmak istedim:

Long-tail Kelimelerin Impression ve Click Bilgileri
ggplot2 ile tıklama ve gösterim metriklerinin dağılımını görselleştirebiliriz:
library(ggplot2)
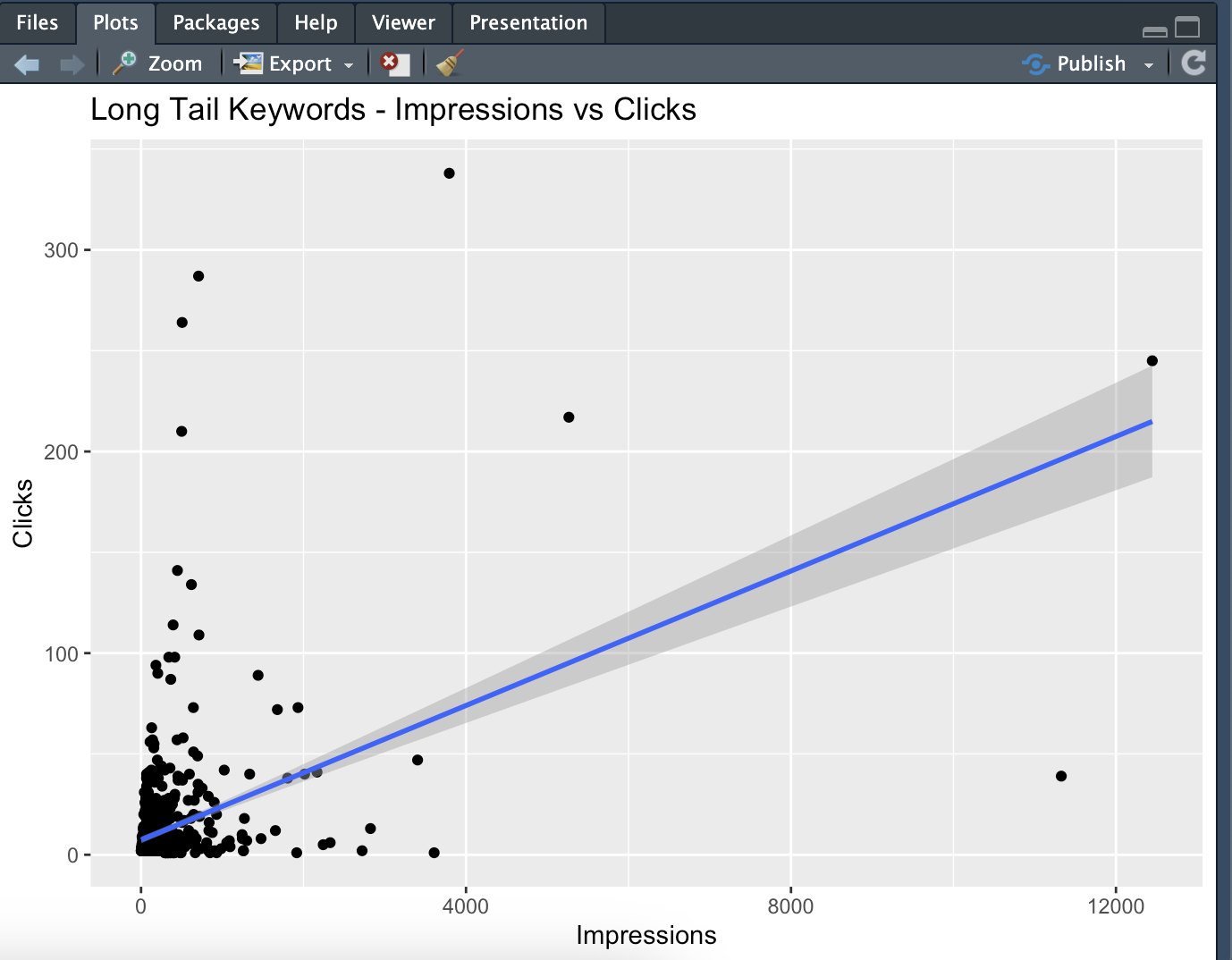
ggplot(long_tail_data, aes(x=Impressions, y=Clicks)) +
geom_point() +
geom_smooth(method="lm") +
labs(title="Long Tail Keywords - Impressions vs Clicks")

İyi performans gösteren long tail kelimeleri tespit ederek yeni içerik stratejileri geliştirebilirsiniz. Çalışmanın doğal sonucu olarak zaten kelimeler 0’a en yakın noktalarda toplanacaktır, amacımız bizim için değerli olan kelimeleri tespit edebilmek:
Bu grafiğin yanı sıra biraz daha detaylı grafik oluşturabiliriz.
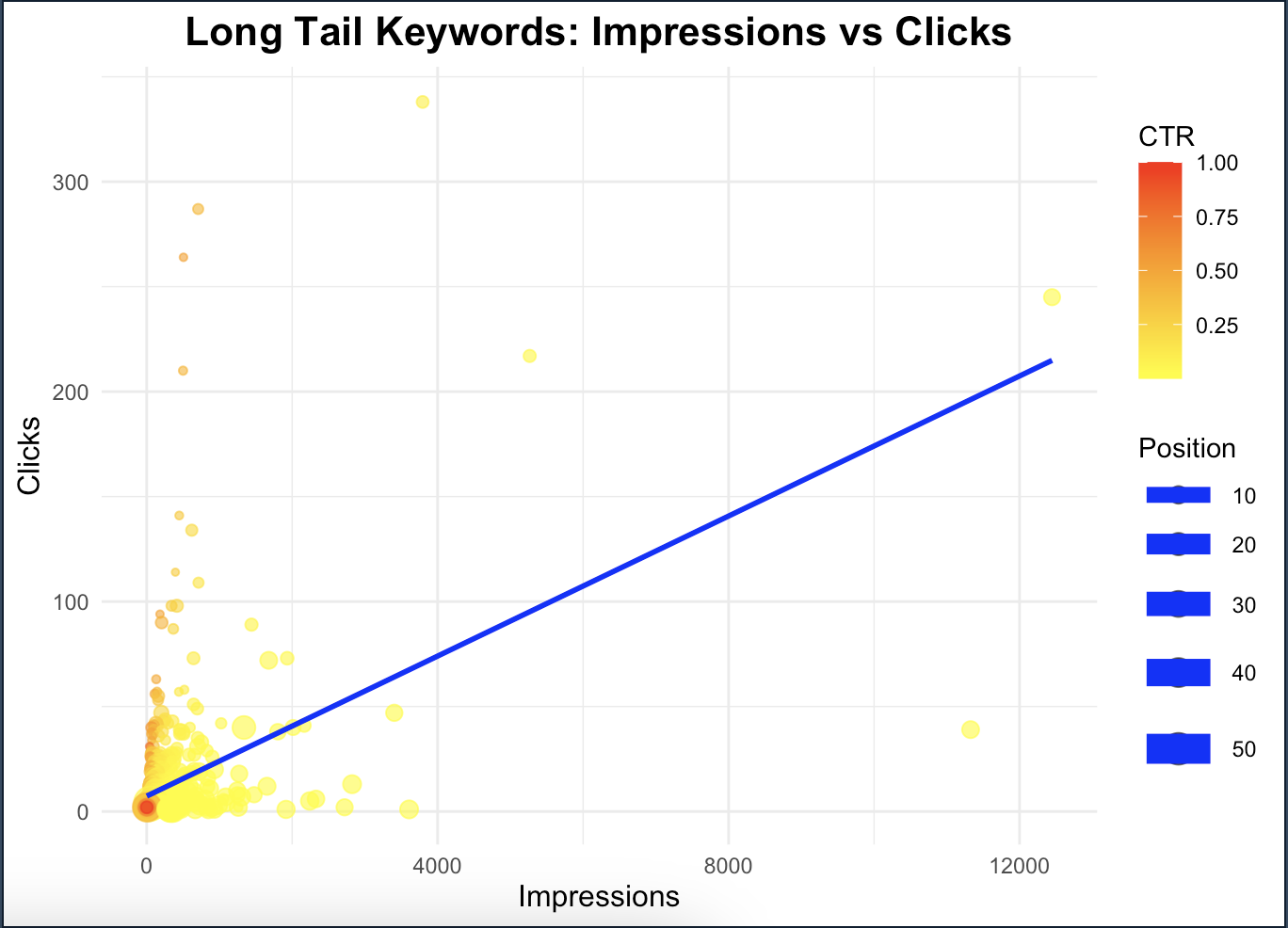
Regresyon çizgisiyle, impression sayısı arttıkça click sayısının nasıl değiştiğini görebilirsiniz. Eğimin pozitif olması, gösterimlerin arttıkça tıklamaların da arttığını gösterir; fakat eğim çok dik değilse bu artışın sınırlı olduğunu gösterir.
Noktaların renkleri ise CTR'ı temsil ediyor. Sarı renkler düşük CTR'ı, kırmızı renkler ise yüksek CTR'ı göstermektedir. Eğer daha yüksek CTR'a sahip kırmızı noktalar genellikle düşük gösterim seviyelerinde yer alıyorsa bunları kontrol edebilirsiniz. Kırmızı (yüksek CTR) noktaların genellikle yüksek gösterim sayılarına mı yoksa düşük gösterim sayılarına mı yakın olduğuna dikkat edebilirsiniz. Bu sayede belirli kw’lerin gösterimlerde ne kadar etkilli olduğunu anlayabilirsiniz:
Bu grafiği oluşturmak için kodlar:
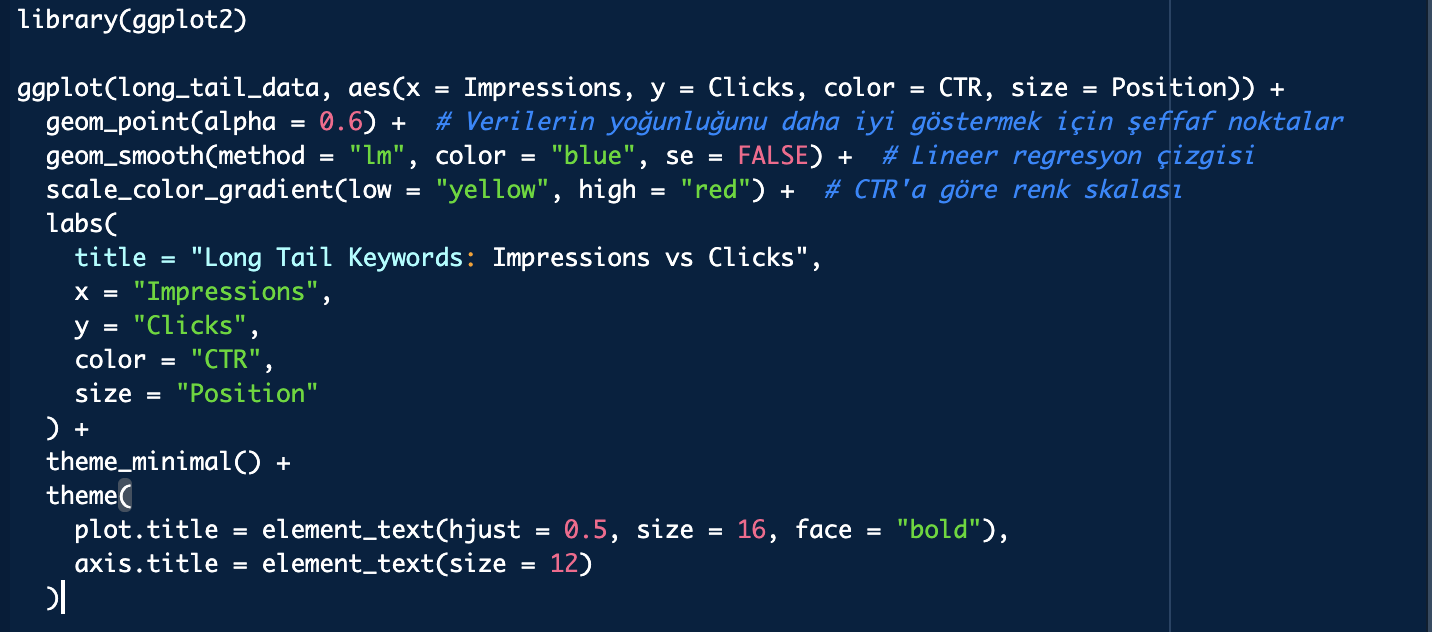
library(ggplot2)
ggplot(long_tail_data, aes(x = Impressions, y = Clicks, color = CTR, size = Position)) +
geom_point(alpha = 0.6) + # Verilerin yoğunluğunu daha iyi göstermek için şeffaf noktalar
geom_smooth(method = "lm", color = "blue", se = FALSE) + # Lineer regresyon çizgisi
scale_color_gradient(low = "yellow", high = "red") + # CTR'a göre renk skalası
labs(
title = "Long Tail Keywords: Impressions vs Clicks",
x = "Impressions",
y = "Clicks",
color = "CTR",
size = "Position"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
axis.title = element_text(size = 12)
)
Word Cloud Oluşturma
Kelime bulutları oluşturmak için wordcloud paketini kullanabilirsiniz. Aşağıda yer alan scale = c(3, 0.5) parametresi, kelimelerin boyutunu belirler.
- 3: Word cloud içindeki en büyük kelimenin boyutunu belirler. Buradaki 3 sayısı, en çok tıklanan/gösterilen kelimenin boyutunu temsil eder.
- 0.5: Word cloud en küçük kelimenin boyutunu belirler. Buradaki 0.5 sayısı, en az tıklanan/gösterilen kelimenin boyutunu temsil eder.
library(wordcloud)
wordcloud(long_tail_data$Query, long_tail_data$Clicks, scale = c(3,0.5), max.words = 50)
library(wordcloud)
library(RColorBrewer)
wordcloud(
words = long_tail_data$Query,
freq = long_tail_data$Clicks,
scale = c(3, 0.5),
max.words = 70, #Gösterilecek maksimum kelime sayısı
random.order = FALSE, #En sık kullanılan kelimenin ortada yer alması
rot.per = 0.35, #Döndürülen kelimelerin oranı
colors = brewer.pal(8, "Dark2"), #Renk paleti
family = "serif" #Yazı tipi
)

Örnek çıktı: (Bunu çok daha farklı gösterebilirsiniz, kod içinde oynamalar yapmanız mümkün)

Korelasyon Isı Haritası
Korelasyon ısı haritaları (Correlation Heatmap) ile long tail kelimelerin farklı metrikler (tıklamalar, gösterimler, CTR) arasındaki ilişkisini görmek için kullanılabilir ve bunun sonucunda korelasyon matrisi oluşturabilirsiniz. Korelasyonun zaten ne olduğunu önceki yazımda anlatmıştım.
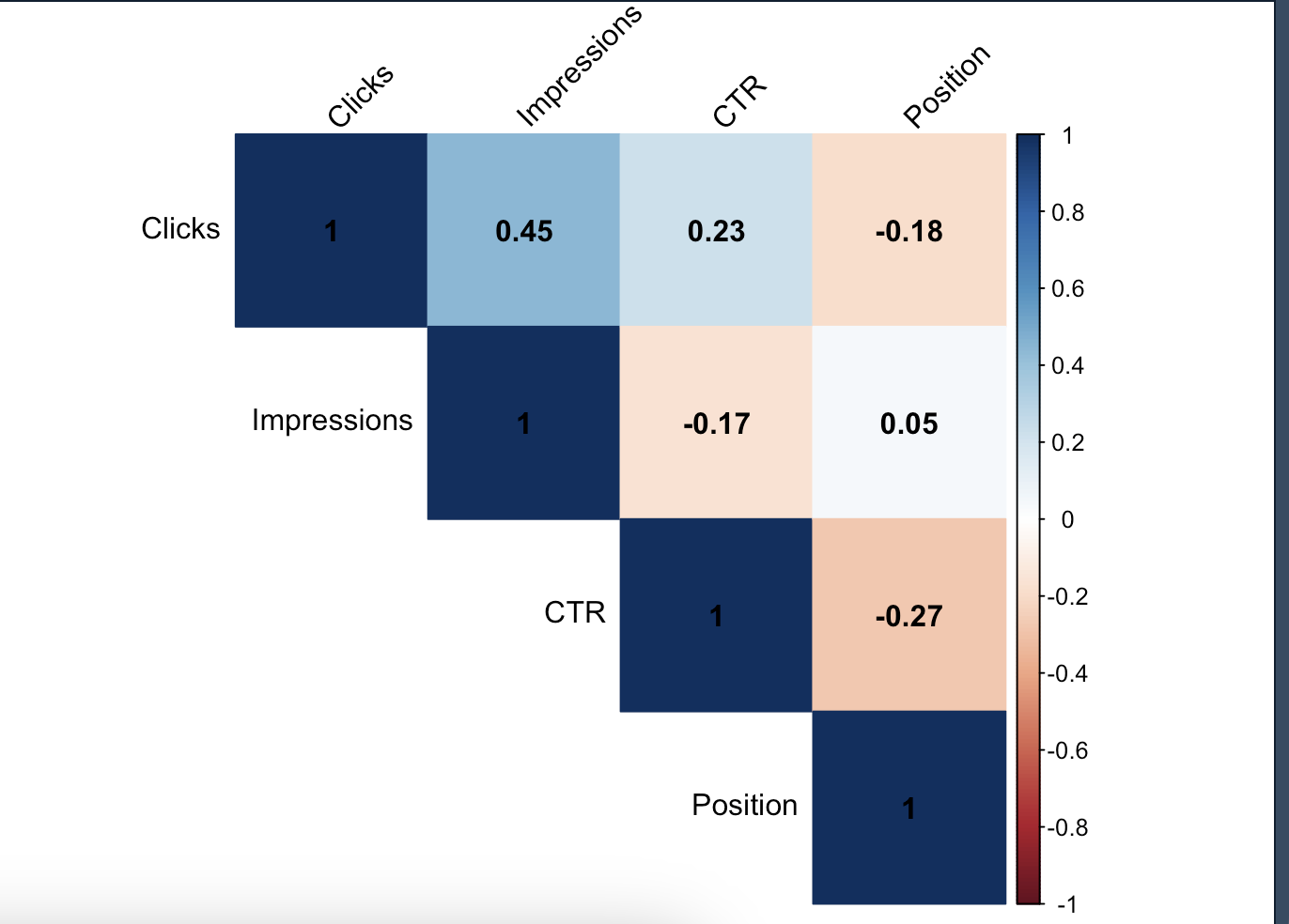
Matrise göre;
CTR ve Position Arasındaki Korelasyon: CTR ile Position arasında negatif bir korelasyon görünüyor. Yani, ortalama pozisyonun artması (örneğin 1. sıraya yakın olma), CTR'ın artmasıyla sonuçlanır. Bu durum genellikle negatif bir korelasyon katsayısıyla ifade edilir.
Impressions ve CTR Arasındaki Korelasyon: Impressions ve CTR arasında genellikle düşük ve negatif bir korelasyon görünüyor. Yüksek gösterim sayılarına sahip kelimeler her zaman yüksek CTR'a sahip olmayabilir; çünkü bu kelimeler daha geniş bir kitleye hitap ettikleri için meta tag açısından hedeflenmemiş olabilirler:
İlgili kodlar:
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
if (!require("magrittr")) {
install.packages("magrittr")
library(magrittr)
}
library(corrplot)
numeric_data <- long_tail_data %>%
select(Clicks, Impressions, CTR, Position) %>%
cor()
corrplot(numeric_data, method = "color", type = "upper",
tl.col = "black", tl.srt = 45, addCoef.col = "black")
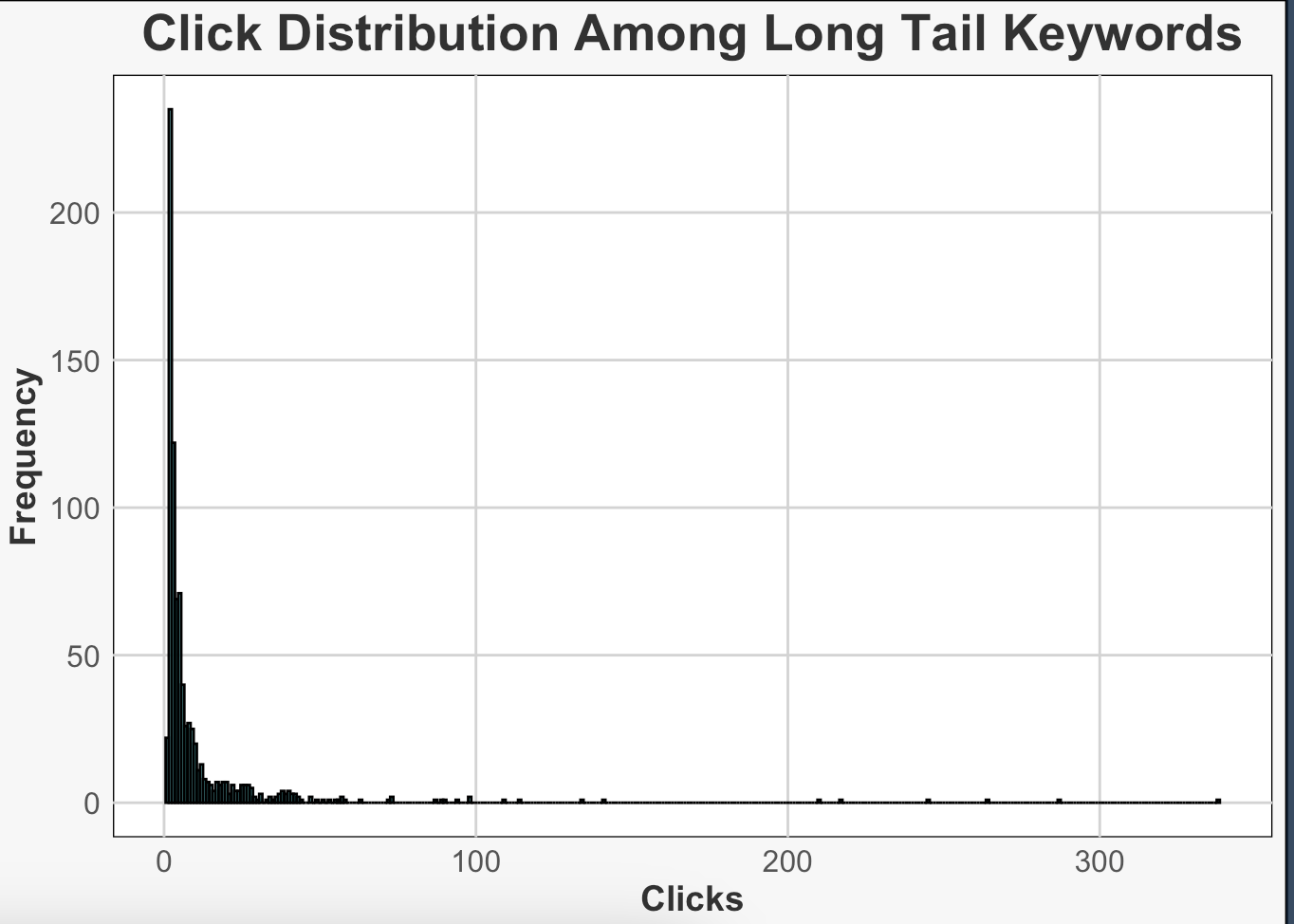
Long-tail Keywords Click Distribution
Long-tail kelimelerin tıklamaların nasıl dağıldığını bu grafik ile görebiliriz. Genellikle, long tail anahtar kelimelerde daha az tıklama beklenir, bu da histogramların normale göre biraz daha uzun ve büyük olmasına sebep olabilir. Aşağıdaki grafik log tail seçiminin bizim tanımımıza göre doğru olduğunu ve tıklamaların yine beklediğimiz gibi çok az olduğunu göstermektedir. Amacımız yine bu kelimeleri tespit edip içerik planlarında yer almalarını sağlamak ve CTR artırmak için meta tags kurguları ya da heading tag kısımlarında geliştirmeler olabilir:
library(ggplot2)
ggplot(long_tail_data, aes(x = Clicks)) +
geom_histogram(
binwidth = 1,
fill = "#00BFC4",
color = "black", # Çerçeve rengi
alpha = 0.7 # Şeffaflık ekleyerek renkleri daha yumuşatır
) +
labs(
title = "Click Distribution Among Long Tail Keywords",
x = "Clicks",
y = "Frequency"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5, size = 20, face = "bold", color = "#333333"),
axis.title.x = element_text(size = 14, face = "bold", color = "#333333"),
axis.title.y = element_text(size = 14, face = "bold", color = "#333333"),
axis.text = element_text(size = 12, color = "#555555"),
panel.grid.major = element_line(color = "#d3d3d3"),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "white"),
plot.background = element_rect(fill = "#f7f7f7")
)
Keyword Heatmap
Long-tail kelimelerin CTR ve click değerlerini hızlıca görebilirsiniz. Grafikte çok koyu mor olanlar click sayısının yüksek olduğunu gösteriyor. Örnek olması amacıyla top 10 kelime için grafiği oluşturdum, tüm kelimeleri grafiğe dökmeniz grafiği anlamsızlaştırır:
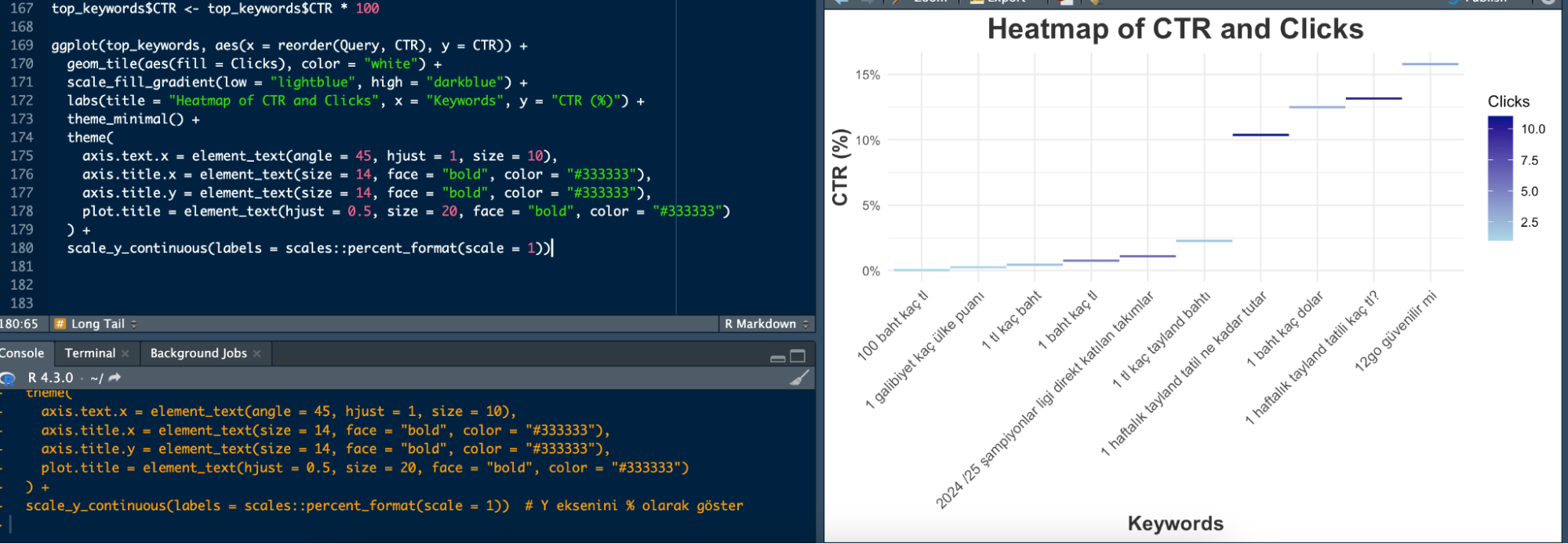
top_keywords$CTR <- top_keywords$CTR * 100
ggplot(top_keywords, aes(x = reorder(Query, CTR), y = CTR)) +
geom_tile(aes(fill = Clicks), color = "white") +
scale_fill_gradient(low = "lightblue", high = "darkblue") +
labs(title = "Heatmap of CTR and Clicks", x = "Keywords", y = "CTR (%)") +
theme_minimal() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1, size = 10),
axis.title.x = element_text(size = 14, face = "bold", color = "#333333"),
axis.title.y = element_text(size = 14, face = "bold", color = "#333333"),
plot.title = element_text(hjust = 0.5, size = 20, face = "bold", color = "#333333")
) +
scale_y_continuous(labels = scales::percent_format(scale = 1))
İsterseniz kelimelerin frekans değerlerini bulup bunları aşağıdaki gibi sıralayabilirsiniz:

Interactive Long Tail Keywords Plot
Grafik üzerinde noktaların üzerine gelince interaktif bir şekilde kelimeleri incelemek isterseniz bu grafik türünü kullanabilirsiniz. Noktaların renkleri, CTR’ı gösterir. Yüksek CTR'a sahip kelimeler genellikle daha sıcak renklere boyanır. Yüksek CTR'lı kelimelerin genel olarak daha iyi pozisyonlarda mı yoksa belirli bir gösterim aralığında mı bulunduğunu inceleyebilirsiniz. Nokta boyutları, pozisyonu temsil eder. Büyük bir nokta, genellikle daha iyi bir pozisyonu gösterir. Bu durumda, hangi kelimelerin daha iyi pozisyonlarda yer aldığını ve bunların performansını karşılaştırabilirsiniz.
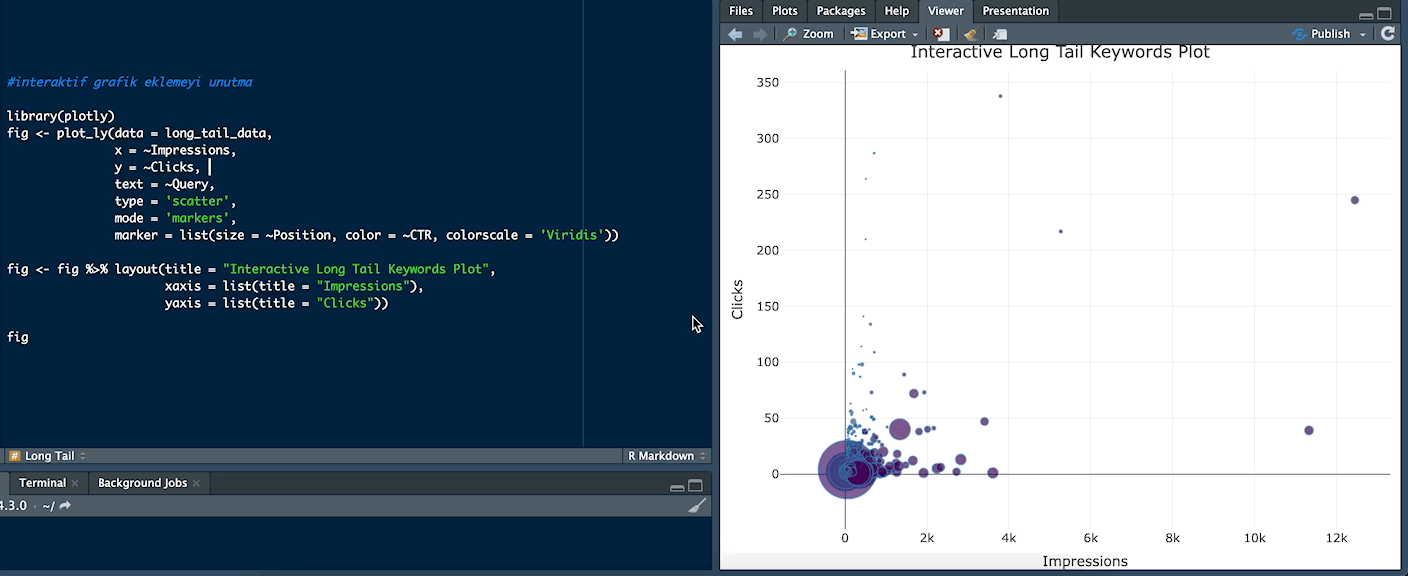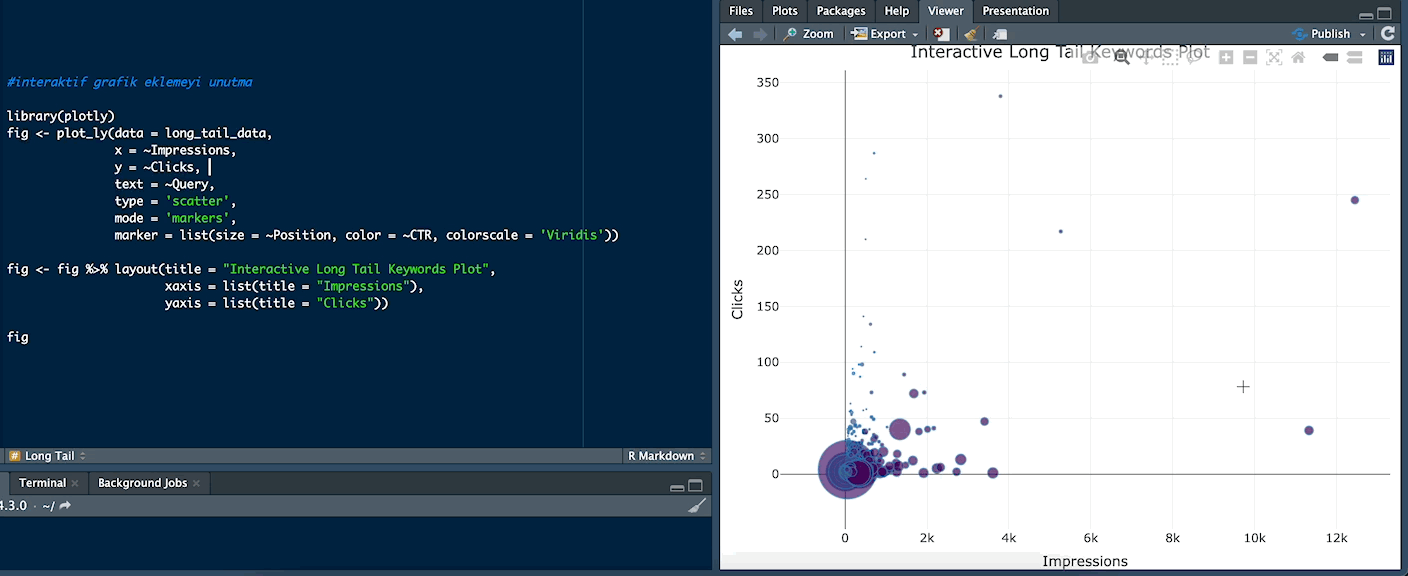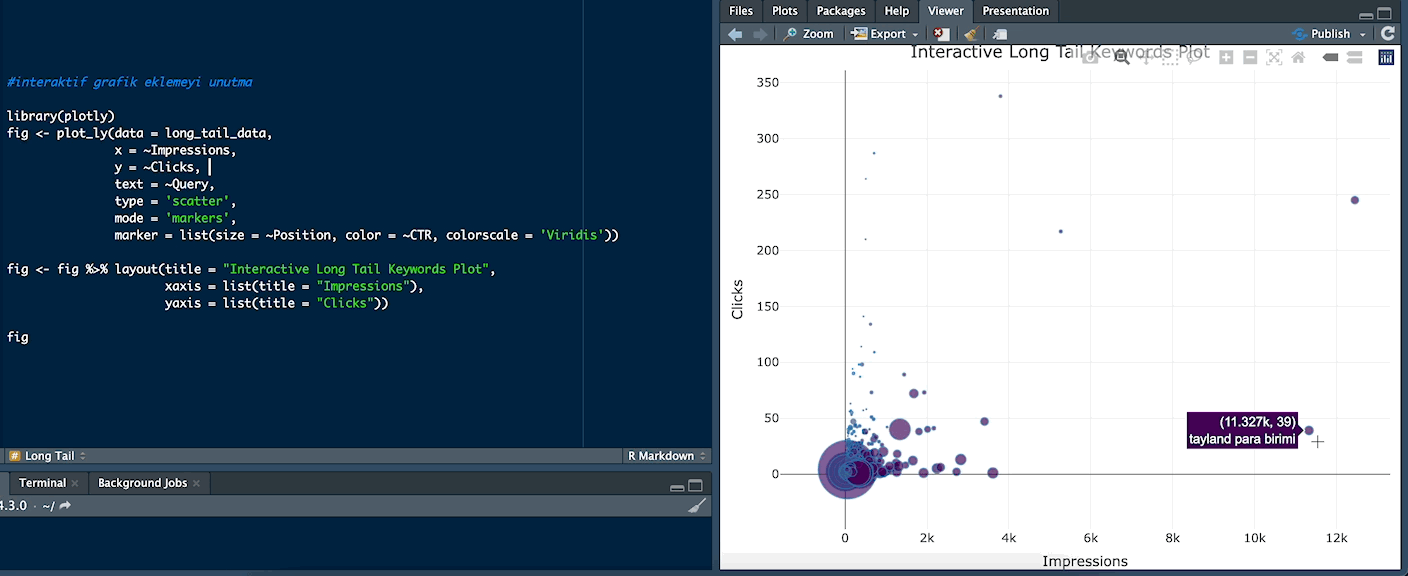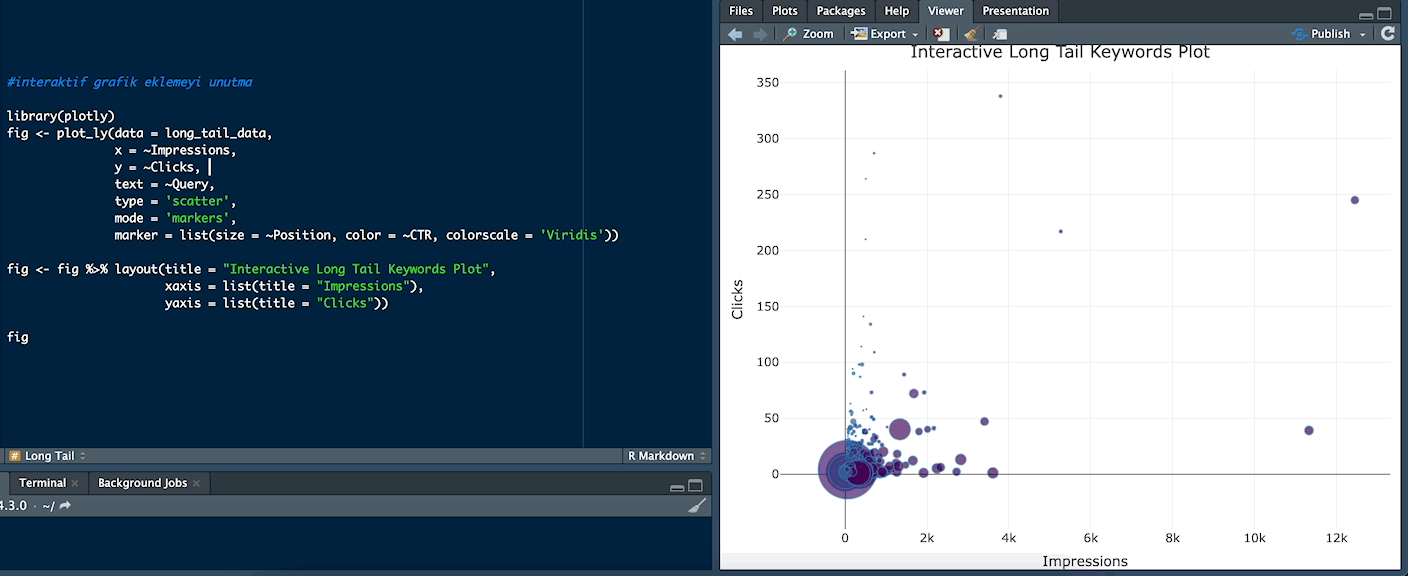
Örneğin “tayland para birimi” kelimesi 11.327 impression alırken 39 click almış:
library(plotly)
fig <- plot_ly(data = long_tail_data,
x = ~Impressions,
y = ~Clicks,
text = ~Query,
type = 'scatter',
mode = 'markers',
marker = list(size = ~Position, color = ~CTR, colorscale = 'Viridis'))
fig <- fig %>% layout(title = "Interactive Long Tail Keywords Plot",
xaxis = list(title = "Impressions"),
yaxis = list(title = "Clicks"))
fig
Umarım long-tail kelimeleri nasıl tespit edebileceğinizi ve bunları görselleştirdikten sonra içerik çalışmalarınızda nasıl kullanabileceğinizi anlatabilmişimdir. Bu verilerden sadece birkaç kelime bile tespit edip içeriklerinizi güncellediğinizde bence çok güzel dönüşler alabilirsiniz. Başka R ve istatistik yazılarında görüşmek üzere :)




