


What is Robots.txt File, and Why is it Important?
Google and other search engines aim to provide their users with the most accurate results in the fastest way possible. The software belonging to these search engines, which we call bots, also crawl web pages and add them to their indexes to present them to users. However, we may not prefer that search engine bots crawl and index some of our pages. In such cases, a simple text file called robots.txt can help us.
What is a Robots.txt File?
Robots.txt is a text file where search engine bots are given some directives and are usually told which pages they can or cannot access. With this file, we can ensure that some of our pages, groups of pages, or even our entire website are not crawled by search engine bots. Some people ask, "Why would I want that?". But in some cases, it can be a very logical move to use the robots.txt file to block our page or pages from crawling.
For example, we may have pages we don't want search engine bots to access and index. Or, because we have many web pages, we may want to make better use of the resources allocated to us by search engine bots, i.e., our crawl budget. Thus, we can ensure that search engine bots are interested in our more critical pages. In such exceptional cases, the robots.txt file can be a lifesaver for us.
Why is Robots.txt File Important?
Search engine bots first examine this file before visiting our website. Then it starts to crawl our web pages in the light of the commands in this file. For this reason, we need to be sure that each order in the robots.txt file is correct. Otherwise, we may have accidentally closed all or a significant part of our website to crawling. This can lead to a major disaster for our SEO performance.
In the other scenario, we can close our unimportant pages to crawling with the robots.txt file to optimize our crawling budget. This can positively impact our SEO performance because we can ensure that search engine bots spend the resources they allocate for our website on our essential pages. The robots.txt file and its commands are necessary for a website.
How to Create a Robots.txt File?
You can use a text editor such as Notepad, TextEdit, etc., to create the robots.txt file. Because if you know the necessary commands, all you need is a simple text file with a "txt" extension.
You can also use free robots.txt creation tools for this process. You can find tools similar to the example screenshot below by searching for "robots.txt generator" on search engines. Using these tools will also reduce the possibility of making mistakes in commands.
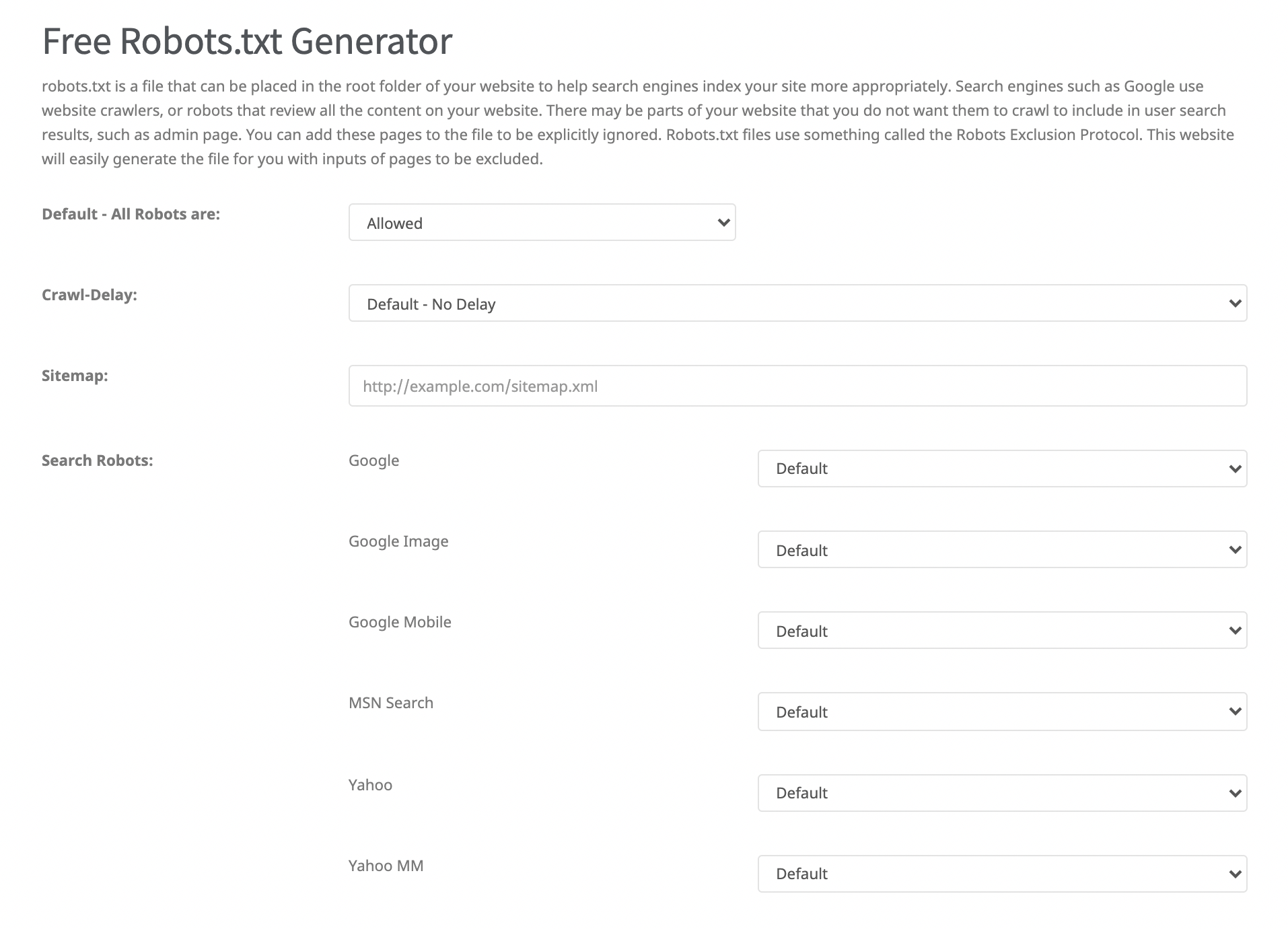
Important Robots.txt Commands
There are some basic commands that you can see in every robots.txt file. You can access a sample robots.txt file, the controls in the file, and their meanings below.
User-agent: This command allows us to select the search engine bot we want to direct. In the example below, the "User-agent: * " command means that we allow all search engine bots to crawl our web pages. We can also use the "User-agent" command more than once to give different directives to search engine bots.
Allow: With this command, we specify the web pages or groups of pages that we want search engine bots to access.
Disallow: With this command, we specify the web pages or groups of pages that we want search engine bots not to access.
Sitemap: With this command, we point search engine bots to the sitemap's address.

In summary, from the example robots.txt file above, we see that this website is open to all bots, but search engine bots do not want search engine bots to access pages with the /demo/ path except the "/demo/example-content" page. Finally, with the "Sitemap" command, the sitemap's address is provided to search engine bots. We can use the above commands more than once and create different strategies.
Example Scenarios
Let's examine a few simple example robots.txt commands together to make the information conveyed more memorable and understandable.

- Website open to all search engine bots
- No page is crawled by search engine bots

- Website open to all search engine bots
- All pages can be crawled by search engine bots

- Website open to all search engine bots
- Do not crawl pages whose URL starts with "/zeo/"

- Website open to all search engine bots
- Do not crawl pages whose URL starts with "/zeo/"
- But scan the "/zeo/team" page

- Googlebot-Image bot should not crawl URLs ending with ".jpg"
Important Note: The "$" at the end of the command means URLs that end this way, while the "/*" before it means whatever precedes the URL.

- Googlebot will not crawl any URL with "/try/" in it
Note: Using "*" in front of and at the end of a command like the one above means that no matter what is in front of or behind it, if it contains "/try/" it will not be crawled.
Robots.txt Test Tool
If you want to make changes to the commands in the Robots.txt file, I recommend using Google's Robots.txt Testing Tool first. You can access the relevant tool here.
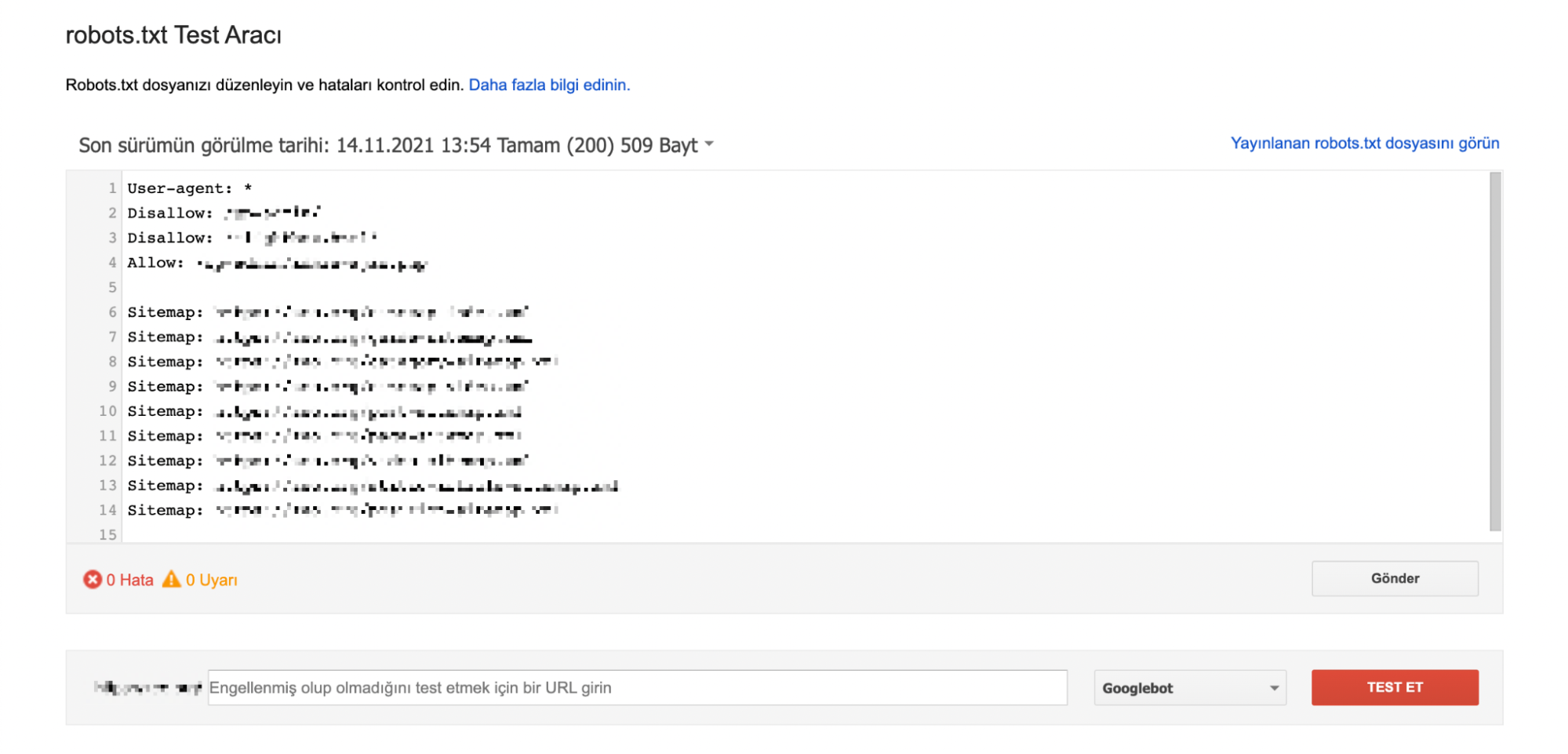
With this tool, you can easily test whether the commands you have added before or the commands you have added for testing on the tool are working correctly. It is especially useful to test whether the sample pages are crawlable with this tool before publishing mixed combinations where you add more than one "Disallow" and "Allow" command.
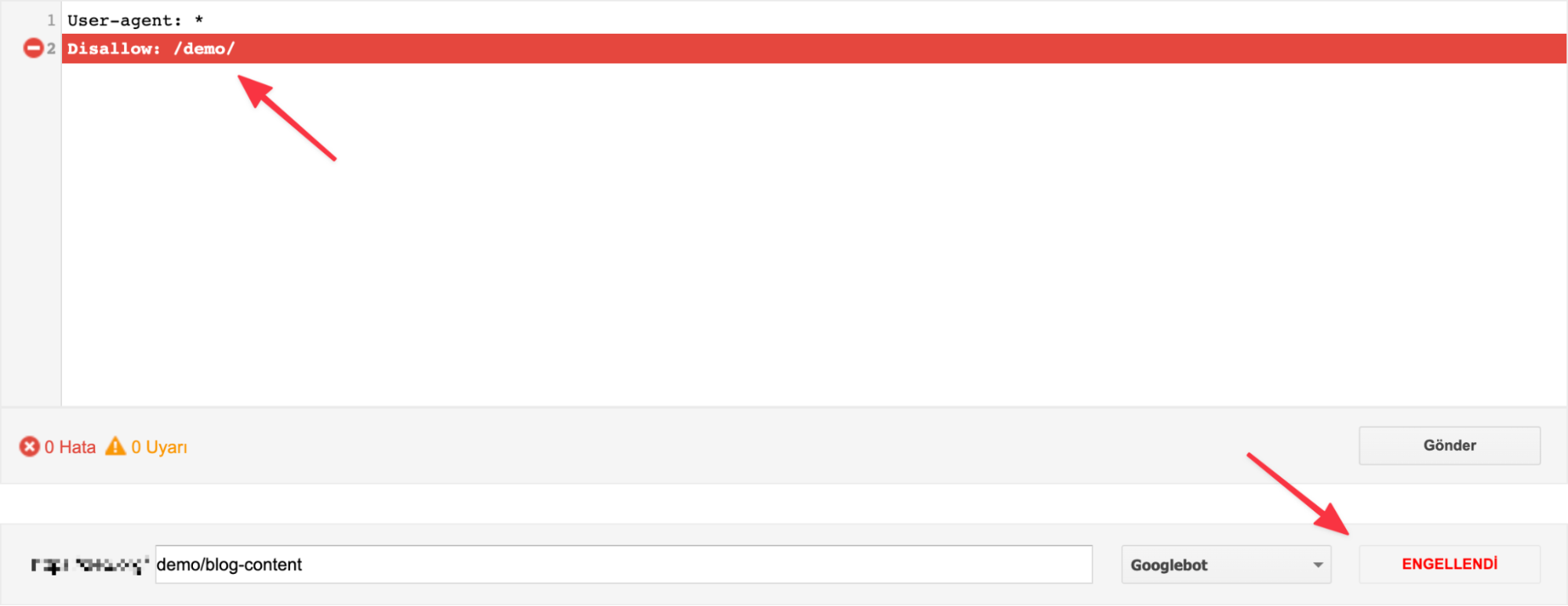
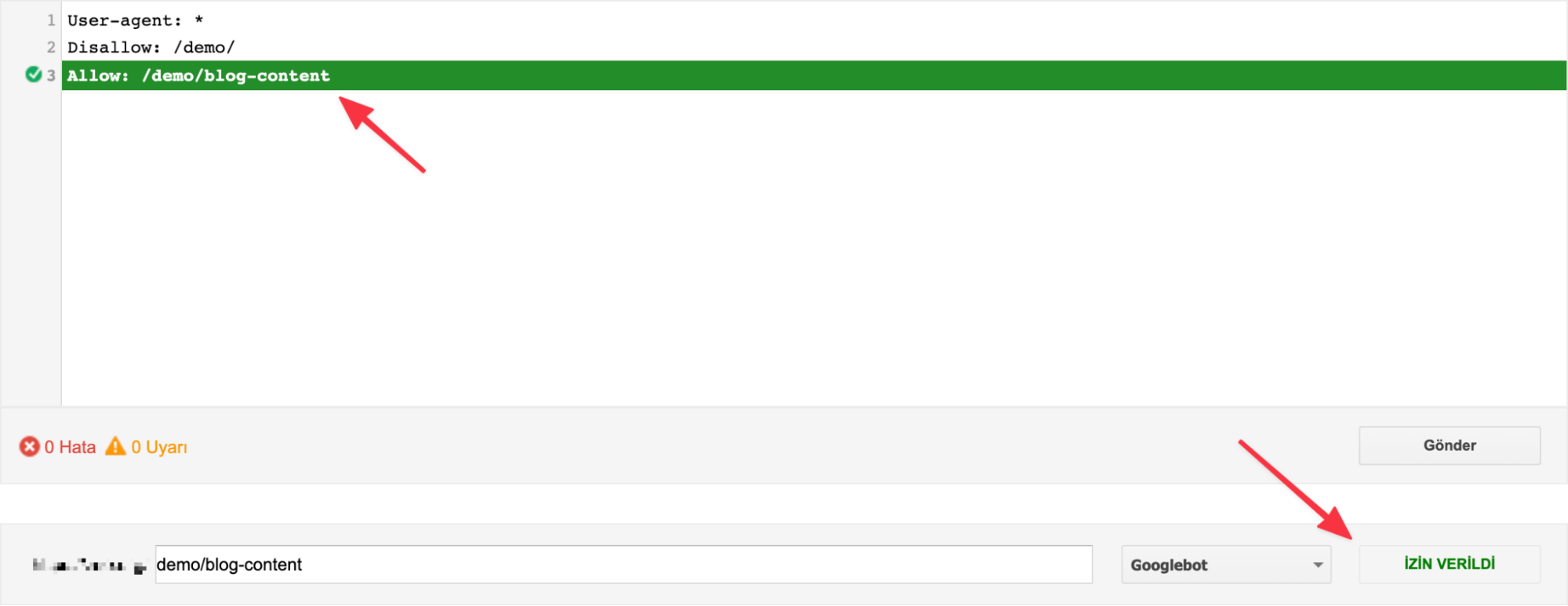
Also, if you have added commands for different search engine bots of Google, you can click on the "Googlebot" button on the bottom right to see if the command you added works for the relevant search engine bot.

If you want to publish the final version of the file after performing the necessary tests, just click the "Submit" button.
Search Console Controls
After logging into the Search Console tool, you can access many details about your indexed or non-indexed web pages by clicking the "Scope" button from the left menu.
After logging in here, you can also see the pages blocked due to the commands in your robots.txt file and the pages indexed despite being blocked.


You may find that the pages you want to be crawled here are blocked due to a command in the robots.txt file, or some of your pages that should not be indexed are in the index. For this reason, it is useful to check the pages here periodically, especially after updating the commands in the robots.txt file.
Important Points and Curiosities
We mentioned how vital the commands in the robots.txt file are. Because a character you use or a small detail about this file can cause many different problems, it is essential to pay attention to some points.
Main directory: Robots.txt file should be located in the leading directory as "example.com/robots.txt".
File name: The file name should be "robots" in lowercase and the file extension should be "txt".
Number of files: You should only have one robots.txt file for a website.
Subdomain-specific robots.txt: You can create a particular robots.txt file for the subdomains you create. Let's say you created a separate subdomain for the blog. The robots.txt address in this example should be blog.example.com/robots.txt.
Case sensitivity: Search engine bots and commands are case sensitive. For example, if you added a base like "Disallow: /demo/", a page like "example.com/DEMO/" would be crawlable. But if you use lowercase for all URLs, you don't need to worry about this.

Sitemap command: Add the sitemap command at the beginning or end of the file. If you have given orders to different search engine bots and the sitemap command is in between them, you may only be pointing your sitemap to that search engine bot.
Robots.txt and the index: The "Disallow" command used in the robots.txt file is not a command to not index the page. It is only about search engine bots not accessing relevant pages. For this reason, the relevant page can continue to be indexed; you can use the "noindex" tag to prevent it from being indexed.
File types: In addition to web pages, you can also give commands for images, videos, audio and resource files through the robots.txt file.
Off-site links: Even if you close a web page to crawl from the robots.txt file, search engine bots can follow these links and index the page if the relevant page is linked to other websites. At this point, it is helpful to use the "noindex" tag again.
Robots.txt requirement: Not every website has to use the robots.txt file. If search engine bots notice no robots.txt file when they visit a website, they can crawl the pages usually and add them to the index. But it is recommended to use it.

Multiple sitemaps: You can add them all in order if you have more than one sitemap. There are no restrictions on this.
How to write commands: You can also write the authorities in the robots.txt file side by side. However, to avoid confusing search engine bots, it is helpful to write each command on a separate line.
User-agent-specific command: When we give a particular order to a user-agent, it will ignore other general commands. For example, we have closed the site to all search engine bots. But on the following line, we have given the order to Googlebot-Image to crawl URLs ending with ".jpg". In this case, even though all pages are closed to search engine bots, Googlebot-Image will ignore the other general commands and crawl URLs ending with ".jpg" because it has been given a particular order.

Pages not to be indexed: If there is a site migration or design change, it would be logical to close the web pages that are not yet ready to be indexed via robots.txt.
In this context, we talked a lot about the robots.txt file, its commands, and why this file is important, and we tried to touch on many important points. I hope it was useful. See you in other blog content. :)
Sources
https://ahrefs.com/blog/robots-txt/
https://yoast.com/ultimate-guide-robots-txt/
https://developers.google.com/search/docs/advanced/robots/intro?hl=tr



















