


R ile Website & Sitemap Crawl ve xPath Kullanımı
R yardımıyla SEO’da neler yapılabileceğini ZEO Blog’ta sizlere aktarmaya çalışıyorum. Daha önceden R’ı kullanarak API ile veri çekilmesi ve Ads tarafında da kullanımına ilişkin konulardan bahsetmiştik. Bugün ise web sitesinin taranması, taranan sitede XPath kullanımı ve sadece sitemap taramak istediğinizde neler yapabileceğiniz konularını ele alacağım. Ayrıca yazıda kullandığım ve yararlandığım paketlerin kaynaklarını da makalenin en altında bulabilirsiniz.
R ile biraz daha işlerinizi kolaylaştırmaya hazır mısınız?
R sayesinde ücretsiz bir şekilde bir web sitesi için crawl gerçekleştirebilir ve XPath komutları ile istediğiniz verileri elde edebilirsiniz. Screaming Frog SEO Spider ya da Deepcrawl gibi araçların yapabileceği birçok işi anlatacağım işlemlerle siz de yapabilirsiniz.
Hızlı bir şekilde kullanımına geçelim. R Studio’nun kurulumu ve diğer ayarlarını anlattığım makalemde kurulumla ilgili bilgileri edinebilirsiniz.
İlk olarak R Crawler ile ilgili paketlerimizi kuruyoruz;
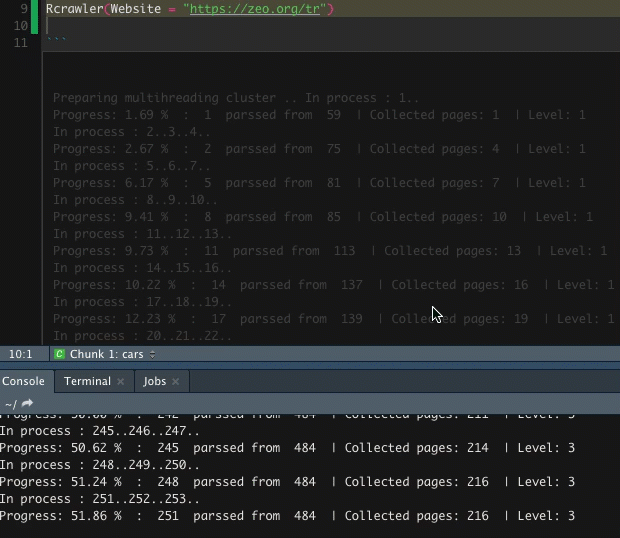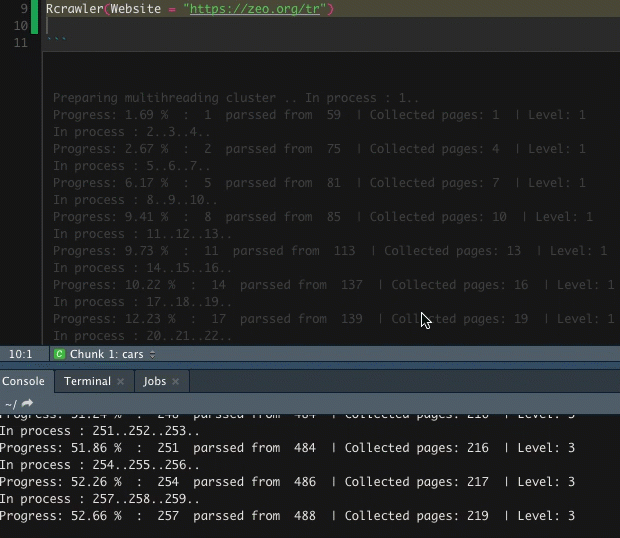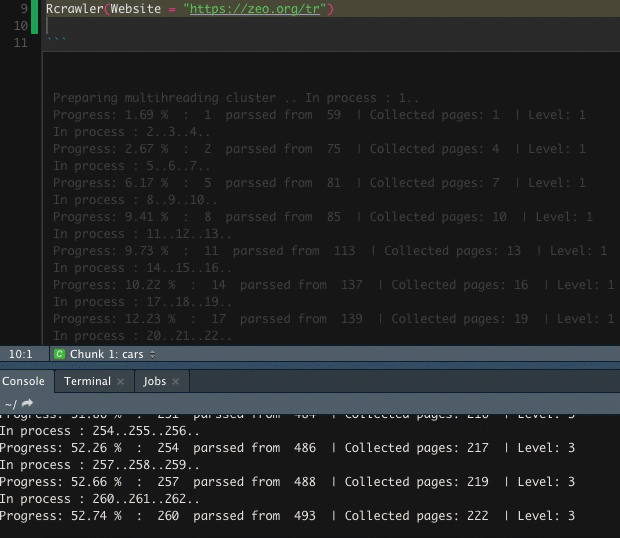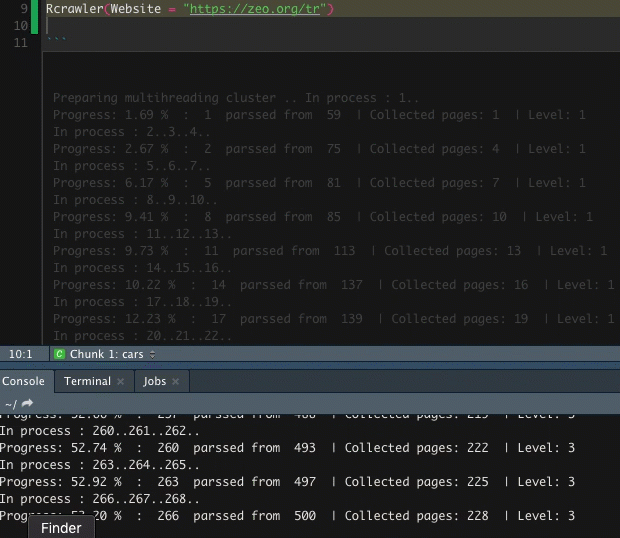
Ardından sitemizi taraması için site adresini girerek taramayı başlatıyoruz. Bu işlemin süresi site büyüklüğüne ve bilgisayarınıza göre değişkenlik gösterecektir.
Rcrawler(Website = "https://zeo.org/tr")
Sadece belirli subfolder taramak isterseniz aşağıdaki kod yeterlidir;
Rcrawler(Website = "https://www.siteadi.com/samet/", dataUrlfilter ="/samet/", crawlUrlfilter="/samet/" )
Ayrıca eğer bir siteyi yayına almadan önce test etmek istiyorsanız ve robots.txt ile bu dosya engelliyse aşağıdaki kodu kullanabilirsiniz;
Rcrawler(Website = "https:/test.zeo.org", Obeyrobots = FALSE)
ZEO’nun web sitesinden hem örnek olması, hem de yazıma hızlıca görselleri eklemek adına 150 URL taradım. Tarama sonuçlarını aşağıdaki kod ile görüntüleyelim;
View(INDEX)
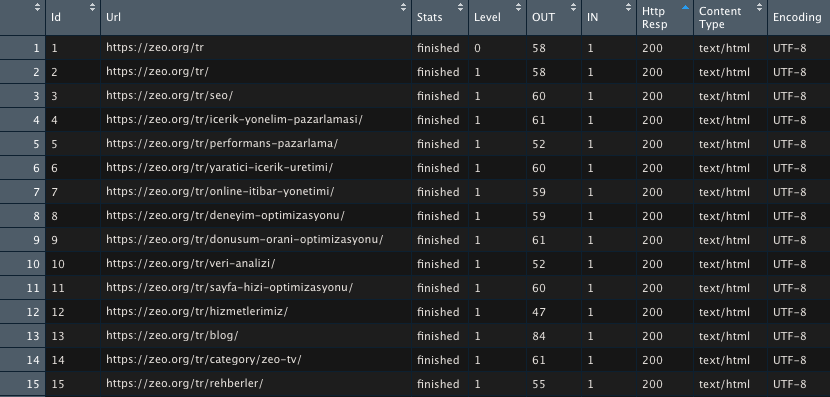 Sitedeki tüm sayfalar statu kodları vs ile geldi. Biraz daha veride detaylara inelim ve title, H1 gibi kısımları XPath kullanarak çekelim;
Sitedeki tüm sayfalar statu kodları vs ile geldi. Biraz daha veride detaylara inelim ve title, H1 gibi kısımları XPath kullanarak çekelim;
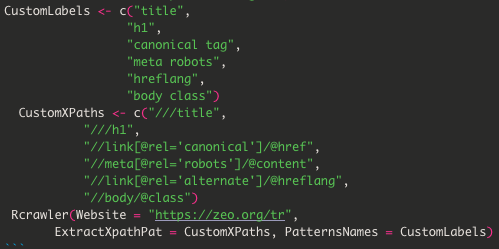
XPath olarak istediğiniz verileri çekmek için istediğiniz XPath komutlarını yazabilirsiniz (description, H2 gibi). Ayrıca ekibimizden Mert’in XPath ile ilgili konuları anlattığı sunumuna mutlaka bakmanızı öneririm.
Crawl tamamlandığında ise bana verileri direkt gösteriyor;
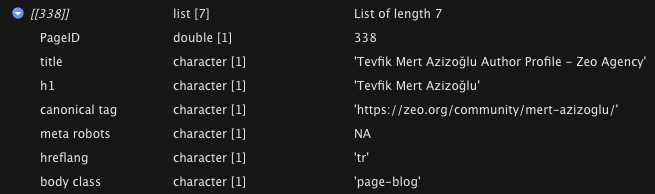
Veriler geldi, ama bu hali benim pek içime sinmedi; biraz daha görselleştirmem lazım bu verileri. Bunun için aşağıdaki data frame’i oluşturabilirsiniz;

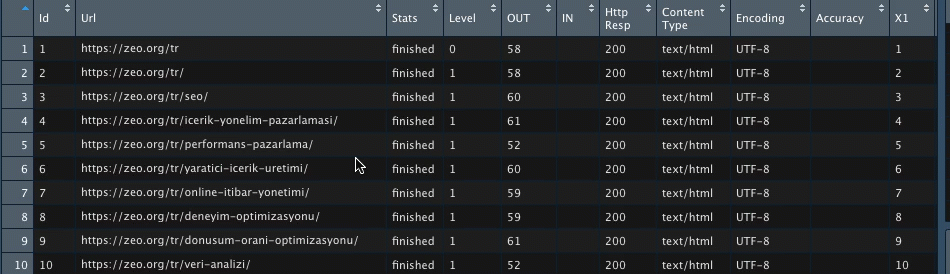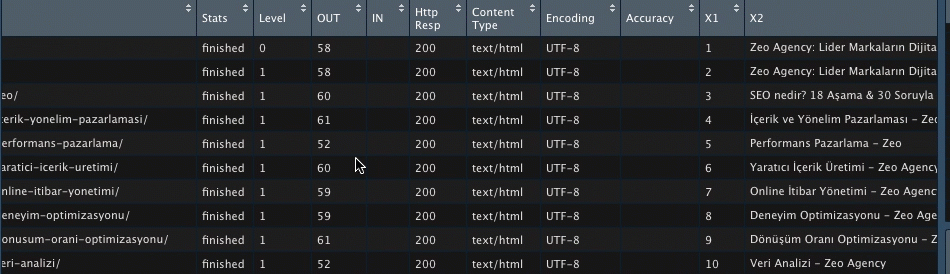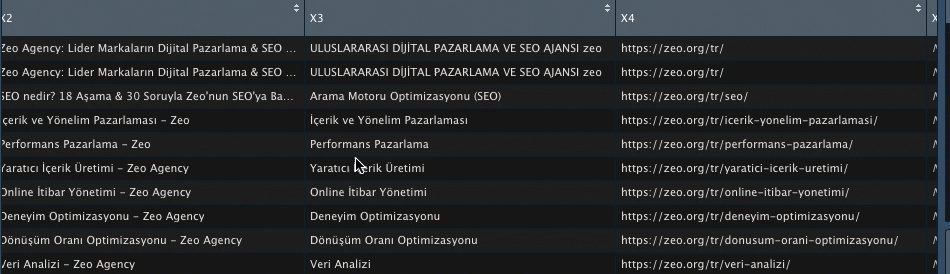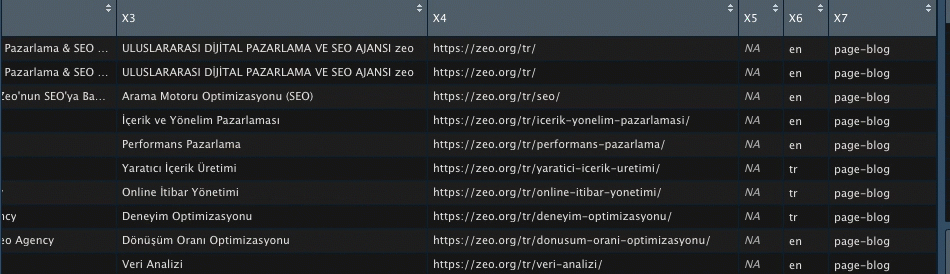
Verilerim artık daha anlaşılır halde;
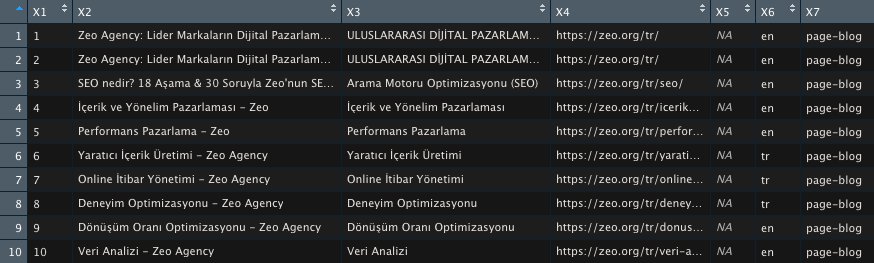
X7 sütununda sayfa türünün page-blog mu yoksa bir tool sayfası mı olduğunu rahatça anlayabiliyorum. Bu veriler sitenizin tasarımında kullanılan kodlara göre değişkenlik gösterecektir.

Tarama sonuçlarıyla XPath kısımlarını merge edersem tablom daha çok veriyi barındıran bir yapı halini alacaktır;

Kodu çalıştırdığımda verilerim birleşmiş halde geliyor;
Görselleştirme yaparken ilgili kişilere X7’nin ne anlama geldiğini anlatmak yerine hemen X7 sütununun ismini değiştirelim. Tablomda 17. satırda bu veri olduğu için köşeli parantez içine 17 yazıyorum;

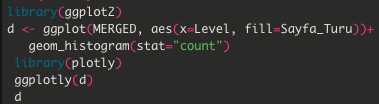
Son olarak verileri görselleştirme kısmına gelelim. Ben “d” isimli bir DF oluşturdum, ona özel aşağıdaki kodlarla grafiği çizdiriyorum. Bu sayede sitemde hangi sayfa türünün daha çok yer kapladığını tespit edebilirim;
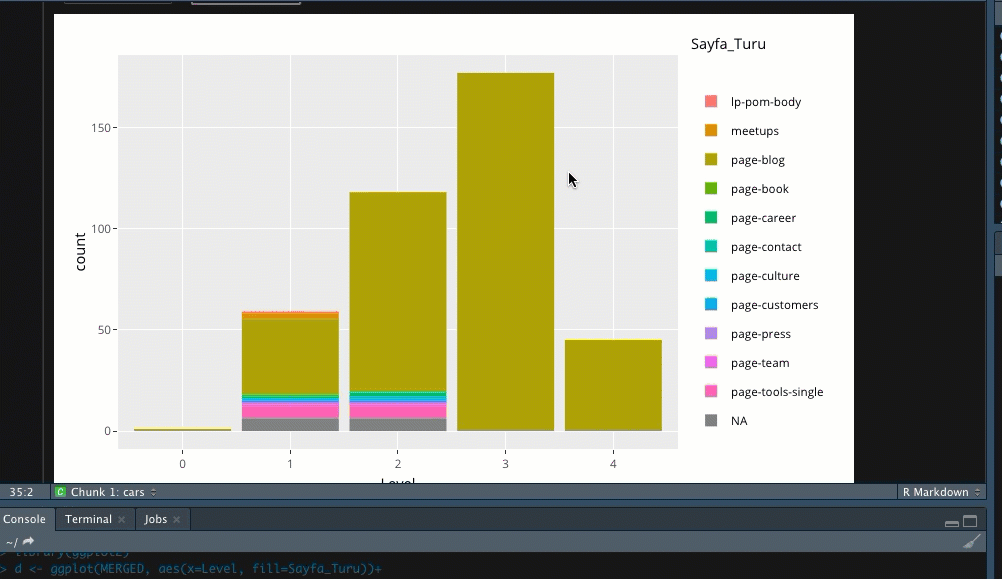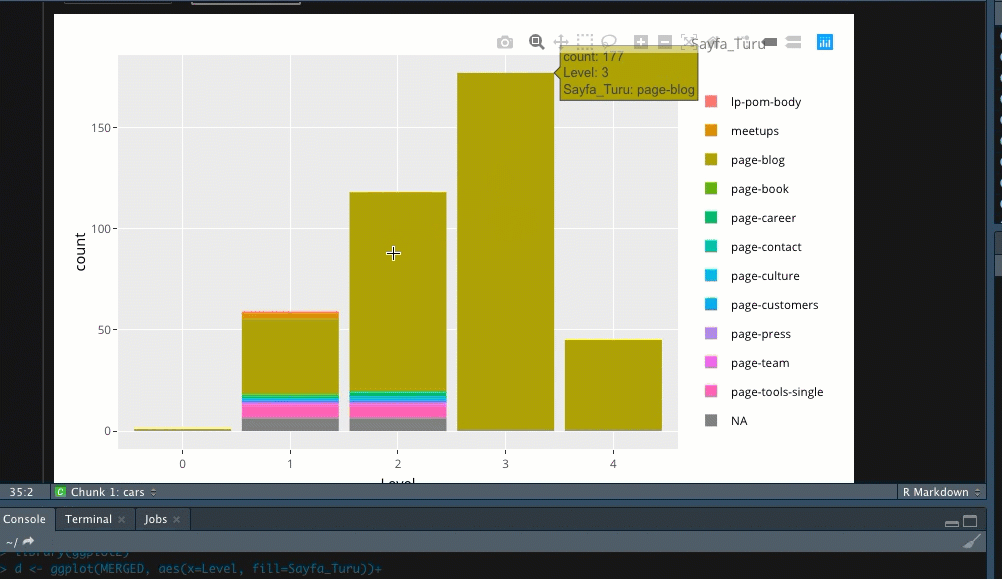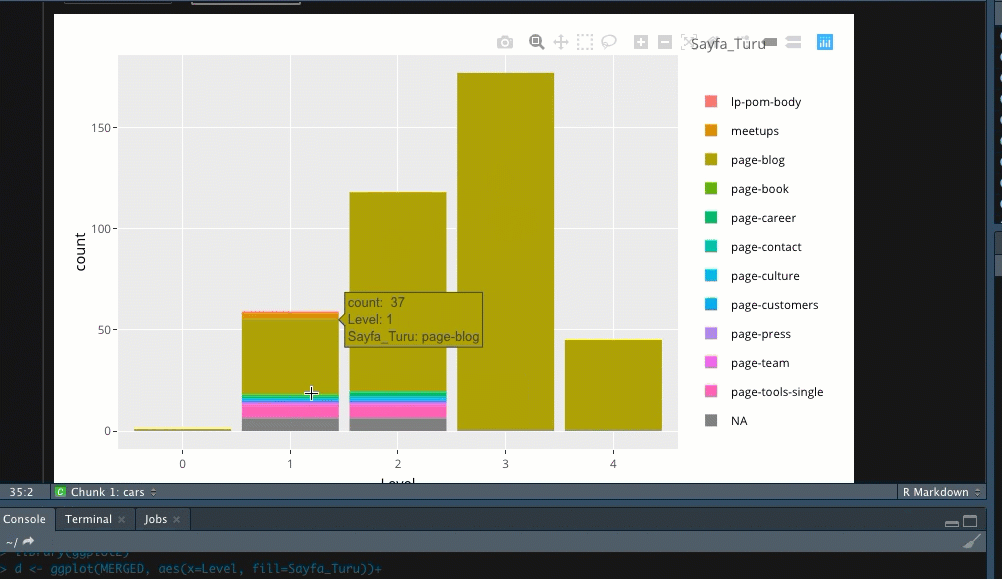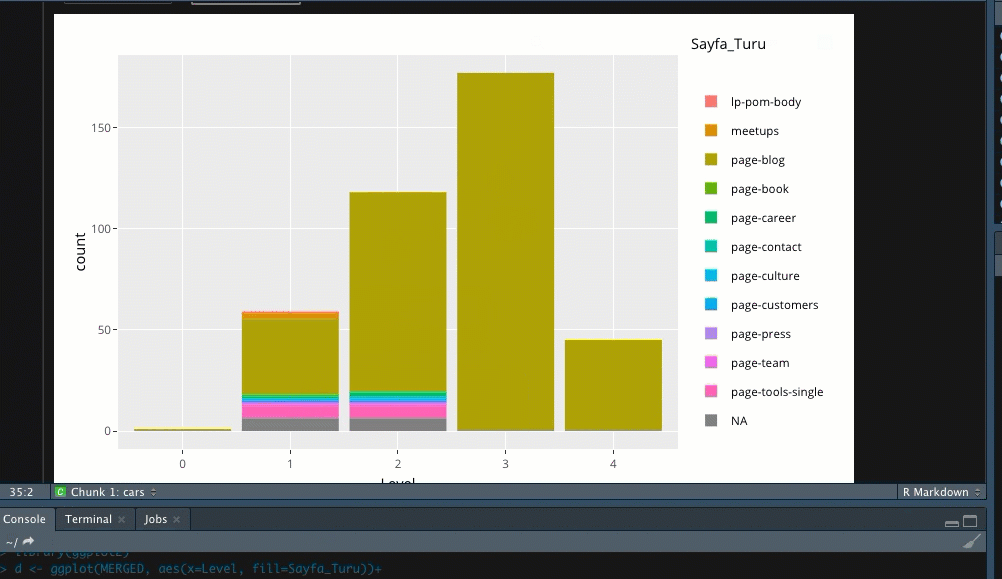
Çalıştırdığımda ise aşağıdaki görüntü ile karşılaşıyorum;
Verileri dışarıya almak için de aşağıdaki kodu çalıştırmanız yeterlidir, dosyanız .csv olarak bilgisayarınıza kaydedilecektir;

Website Crawl ile ilgili tüm kodlar;
install.packages("Rcrawler")library(Rcrawler)Rcrawler(Website = "https://zeo.org/tr")CustomLabels <- c("title", "h1", "canonical tag", "meta robots", "hreflang", "body class") CustomXPaths <- c("///title", "///h1", "//link[@rel='canonical']/@href", "//meta[@rel='robots']/@content", "//link[@rel='alternate']/@hreflang", "//body/@class") Rcrawler(Website = "https://zeo.org/tr", ExtractXPathPat = CustomXPaths, PatternsNames = CustomLabels)samet_veri <- data.frame(matrix(unlist(DATA), nrow=length(DATA), byrow=T))MERGED <- cbind(INDEX,samet_veri)colnames(MERGED)names(MERGED)[17] <- "Sayfa_Turu"View(MERGED)library(ggplot2)d <- ggplot(MERGED, aes(x=Level, fill=Sayfa_Turu))+ geom_histogram(stat="count") library(plotly) ggplotly(d) d write.csv(MERGED, file = "zeo-crawl.csv")
R İle Sitemap Crawl
Web sitesini yukarıda anlattığım şekilde taradık, peki ya site haritalarımızı da tarayarak nasıl daha optimize edilmiş bir site haritası oluşturabiliriz?
Öncelikle toplam yazılacak kod satırı sadece aşağıdaki kadar;
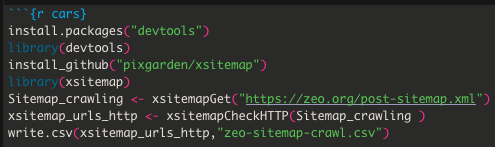
R’da bunu yapabilmeniz için öncelikle aşağıdaki paketi kurmalısınız;
install.packages("devtools")library(devtools)
Ardından Github’a bağlanmanız gerekiyor;
install_github("pixgarden/xsitemap")library(xsitemap)
Taramak istediğiniz sayfanın site haritasının yolunu öğrendikten sonra aşağıdaki gibi ekliyoruz;
xsitemap_urls <- xsitemapGet("<a href="https://zeo.org/post-sitemap.xml">https://zeo.org/post-sitemap.xml</a>")
Statu kodlarına (3XX & 4XX) bakmak için de altta yer alan kodu yazıyoruz;
xsitemap_urls_http <- xsitemapCheckHTTP(xsitemap_urls)
R ilgili kodları çalıştırdıktan sonra direkt taramaya başlıyor, sitenin büyüklüğüne göre tarama işlemi süresi değişkenlik gösterecektir.
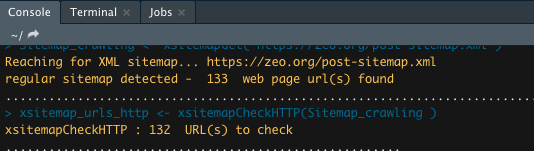
Son olarakta dosyayı kaydetmek için aşağıdaki komutu yazıp çalıştırıyoruz;
write.csv(xsitemap_urls_http,"zeo-sitemap-crawl.csv")
Bilgisayarınıza kaydettiğiniz isimle dosyayı arayın ve açın, ardından .csv’de ufak bir düzenleme yaptıktan sonra site haritanızın taranmış halini aşağıdaki şekilde bulabilirsiniz;

Sitemap crawl işlemi de sadece bu kadar. Sitemap Crawl için gerekli kodlar;
install.packages("devtools")library(devtools)install_github("pixgarden/xsitemap")library(xsitemap)Sitemap_crawling <- xsitemapGet("https://zeo.org/post-sitemap.xml")xsitemap_urls_http <- xsitemapCheckHTTP(Sitemap_crawling )write.csv(xsitemap_urls_http,"zeo-sitemap-crawl.csv")
Kullandığım kodların kaynakları;






















