


What is Log Analysis? Tricks of Log Analysis with Screaming Frog
Log analysis is one of the items that include advanced actions with a technical SEO focus. Therefore, it is very important for improving the opportunities and existing structure of our website. However, it is critical how to make sense of the outputs obtained as a result of log analysis. Because all data in log analysis may not always provide the desired output or action-oriented data.
What is a Log File?
The log file is the data where the actions of all sources sending requests to the website are kept together. By keeping this data daily, it can also allow analysis over a period of time. The log file stored on the server may sometimes not be active by the server providers. As a website owner, it is useful to get information about the fate of the log file to your server provider.
The log file must contain some information in itself. These are; IP address, date, request type, response code, source information, page, and address that made the request.
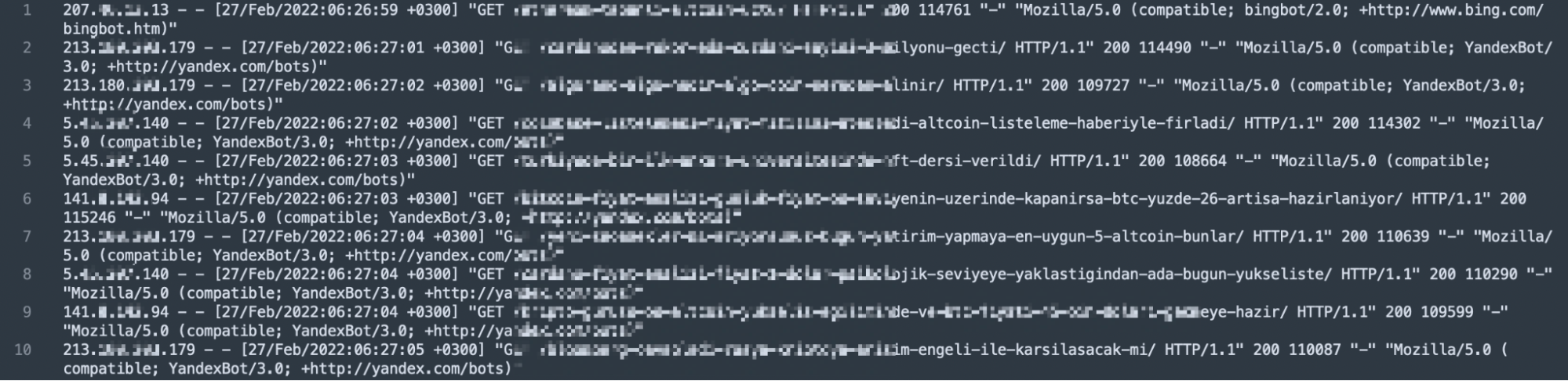
In the light of this information, we can assume that the sample log is kept in the structure 123.45.67.67 - - [27/Feb/2022:22:26:49 +0300] "GET /log-analizi-nasil-yapilir/ HTTP/1.1" 200 115387 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)".
What is Log Analysis?
Log analysis provides information about the requests that search engine spiders send to your website. This information provides the opportunity to analyze how much the site is crawled, which bots visit more, and which response code the page responds with as a result of the request. Thanks to this information, we can have the opportunity to take action and analyze based on data instead of assumptions. You can access comprehensive information and video content using log analysis for SEO, which we have presented in the past months, here.
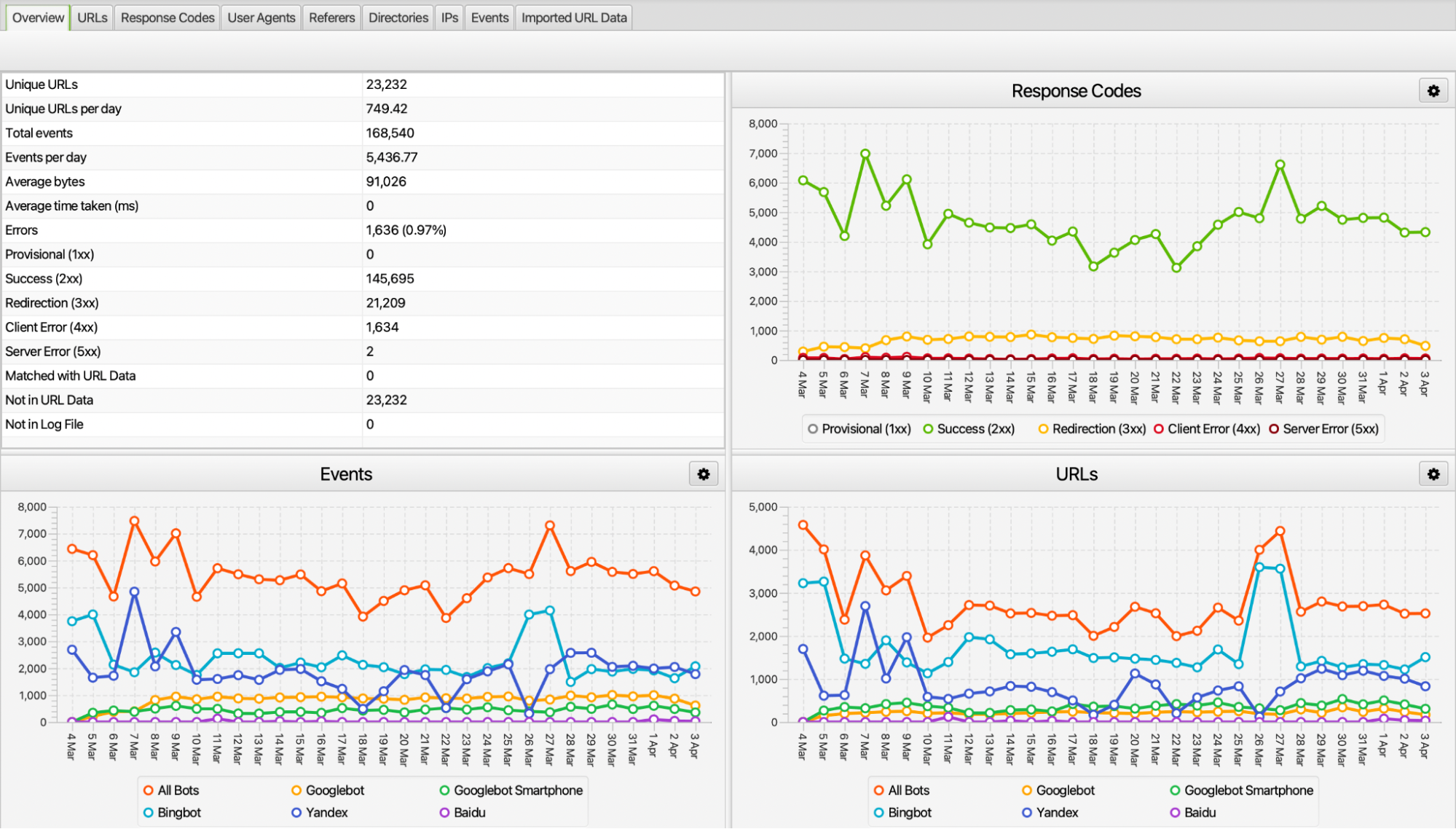
When performing log analysis, you can perform detailed examinations by analyzing the files daily. As a result of these examinations, we can access some outputs such as the following.
- Information about which page or file structure is crawled frequently or not.
- Which response or error code is returned as a result of the request to the page.
- Crawlability checks.
- Crawl budget optimization.
- The importance level information of crawlers by assigning more requests to which pages.
What is Crawl Budget?
Crawl budget refers to the time that search engine bots spend when they can re-crawl the pages they have indexed with the action they have taken to crawl the site. Therefore, the crawl budget of each site is not the same.
In short, it refers to the effort that bots allocate for the number of URLs they can crawl on the website. Reducing the effort here can also be called crawl budget optimization. Because not crawling the pages on the site that we do not target will ensure the efficient use of the crawling budget allocated for the website.
10 Tricks of Log Analysis with Screaming Frog Log Analyzer
The Screaming Frog Log Analyzer tool has many sections and analyzes data in different aspects. Especially in the overview section, we can access information such as the number of requests of crawlers, how many URLs they send requests to, what status code they have, and the number of unique URLs. In fact, it is also very valuable to be able to analyze parts other than this data.
1. Reviewing User Agent Requests
The website receives requests from many crawlers such as Googlebot, YandexBot, bingbot, and Baidu. These requests should be crawlers belonging to the search engines preferred by the users of our website. For example, if there are no or very few users coming to our site from the Bing browser, if we have the output that bingbot sends too many requests in your current log reviews, we will infer that action should be taken here.

We can increase Bingbot's Crawl-delay value to make it come less frequently or we can turn bingbot off from the robots.txt file. In this way, we prevented the user-agent, which does not contribute to our website and receives unnecessary requests, from spending the crawling budget.
2. Response Code Checks
As a result of requests to URLs on the website, the page provides a response code. These response codes express different information within themselves. For example, a 500 response code indicates a server problem, while a 200 response code indicates that the page opened without any problems. In log analysis, we can make some inferences according to the response code. For example, let's assume that we recently redirected AMP pages to their main versions with 301. In this case, the requests to our pages containing /amp may be quite high.
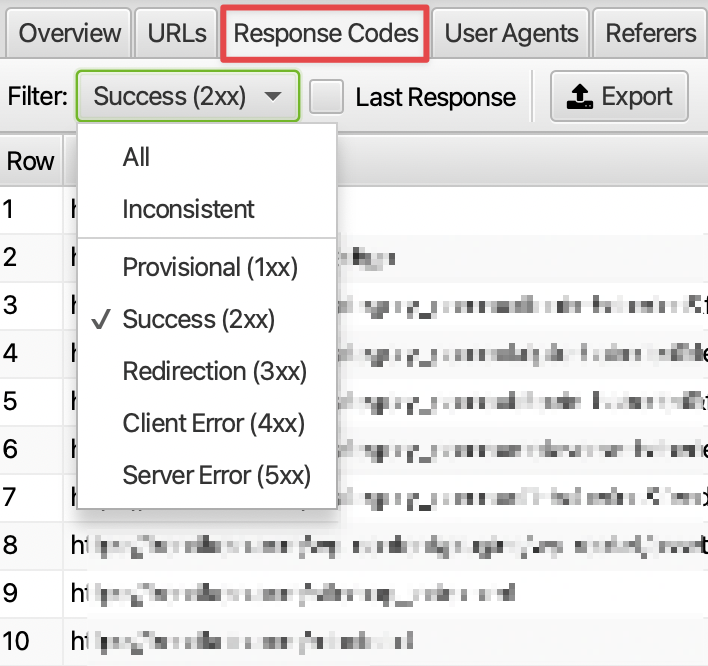
If these URLs are not in the index, we can reduce the unnecessary request by turning off crawling from the robots.txt file. According to the log outputs, different situations may occur and special actions should be taken for these situations.
3. Analyzing the Number of Requests
We can identify the pages where crawlers send the most and least requests. Especially with source filtering, we can examine only HTML or images and access the total number of requests in the relevant date range.
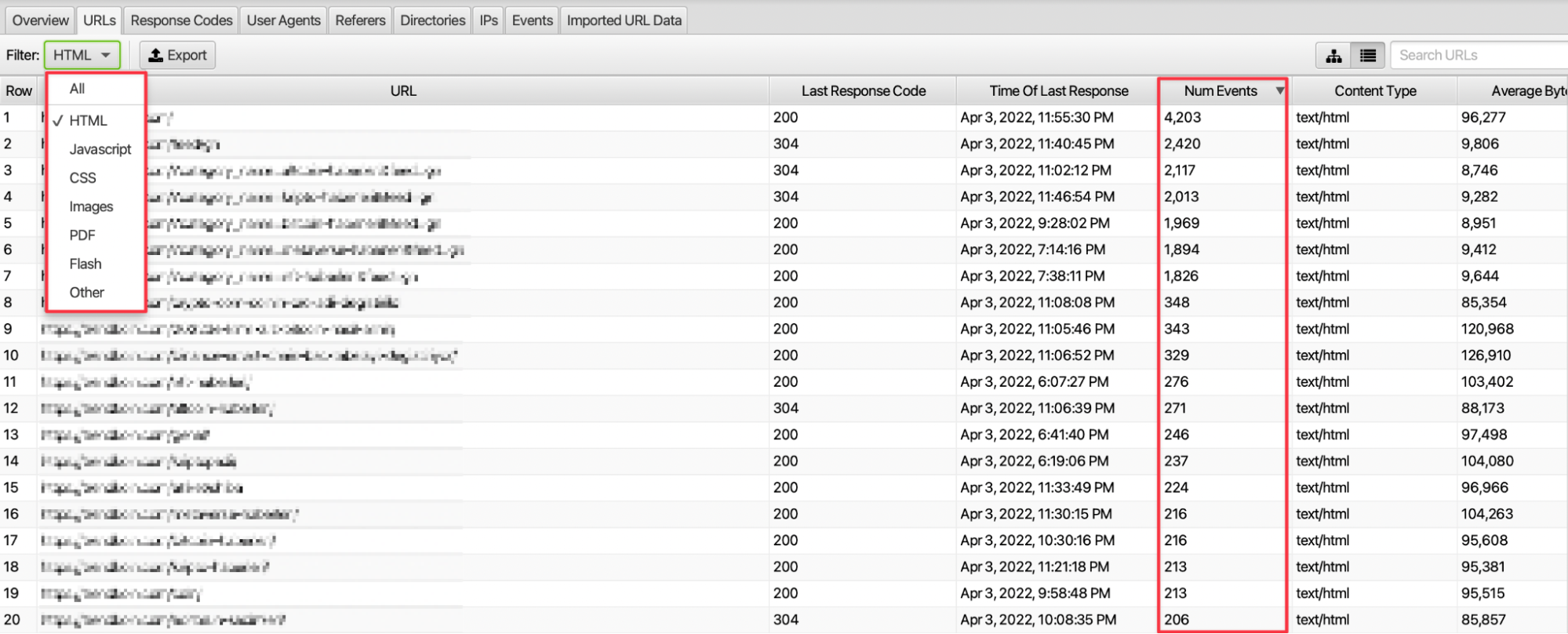
By analyzing the number of requests, we can see which types of resources search engine spiders are sending more crawl requests to.
4. Analyzing The Browsing Frequency of Pages
We can see how often our pages are crawled by crawlers by user-agent and status code. We can also see which bots make more requests to these pages by scrolling the URLs screen to the right. At the same time, in the Response Codes section, there is also information about which response code is encountered in requests to the relevant URLs.
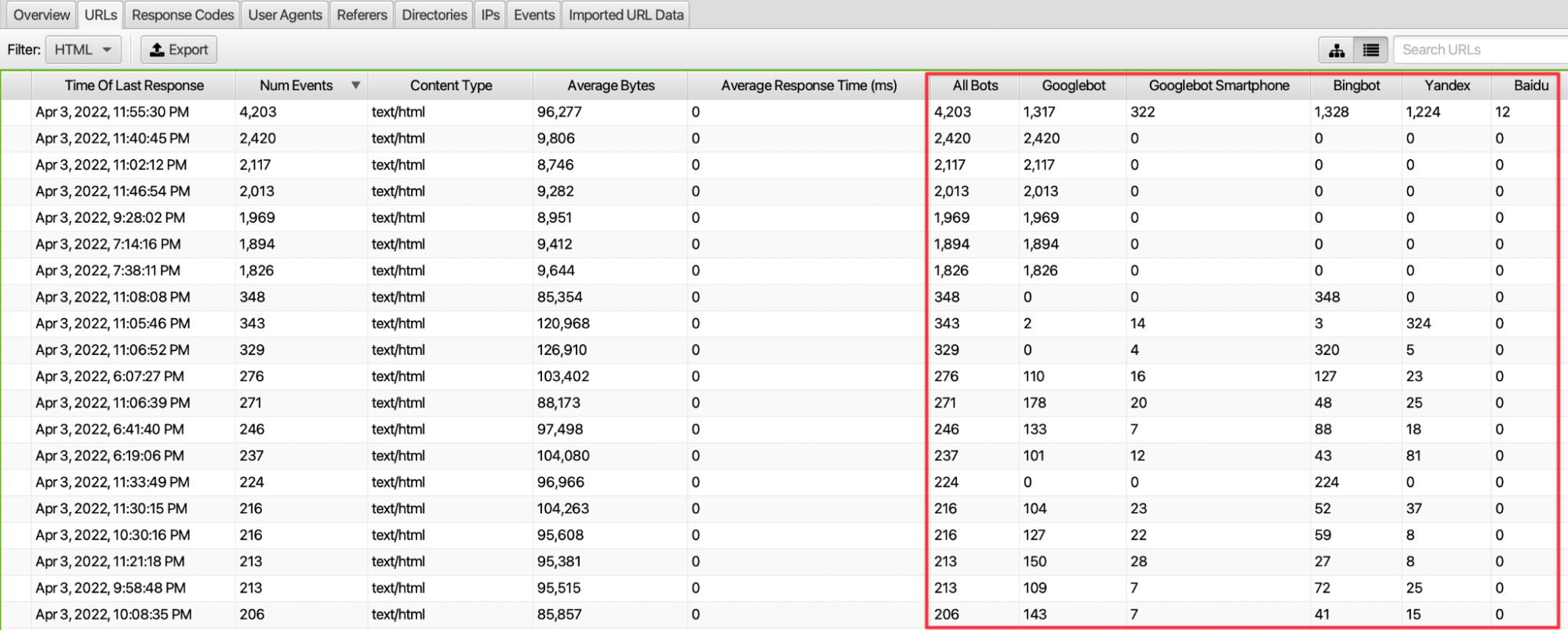
In particular, we can access the average number of requests to our pages by dividing the number of requests to the website by the number of URLs in the relevant date range. By comparing this data with the number of requests to our other pages, we can make inferences about the approach of crawlers to some of our pages. If there are pages that have serious requests but are deemed unnecessary by the crawler, we can take action by closing them to the crawler's crawl.
5. Crawler Crawl Frequency by Directory/Subfolder
We can examine the data in the Directories tab to see the browsing frequency of the subfolder structure in the URL structure of the website. Here, if we consider that the subfolder structure refers to a category or a certain breakdown, we can infer which parts of our website are visited more.
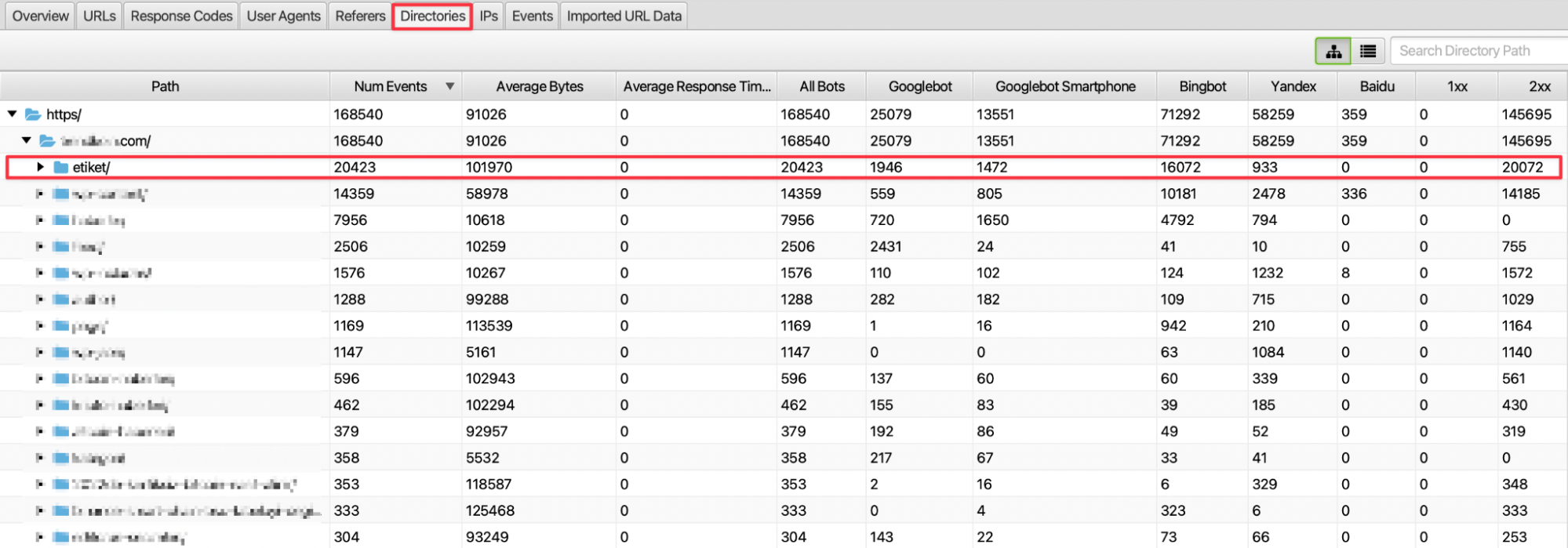
For example, in the image above, it is seen that tag pages receive more requests than other subfolder structures and a significant portion of this request is generated by Bingbot crawling. In this case, we can examine the subfolder structure for crawlers. From the subfolder structures we detect, we can develop an on-site linking strategy to our other relevant categories or pages. In this way, we can direct crawlers to our other relevant pages and perform a more effective scan.
6. Detection of High Dimensional Sources
In order to use the crawling budget allocated by crawlers to the website efficiently, we should check the size of our resources. By optimizing high-sized resources, we can ensure effective use of the crawling budget.
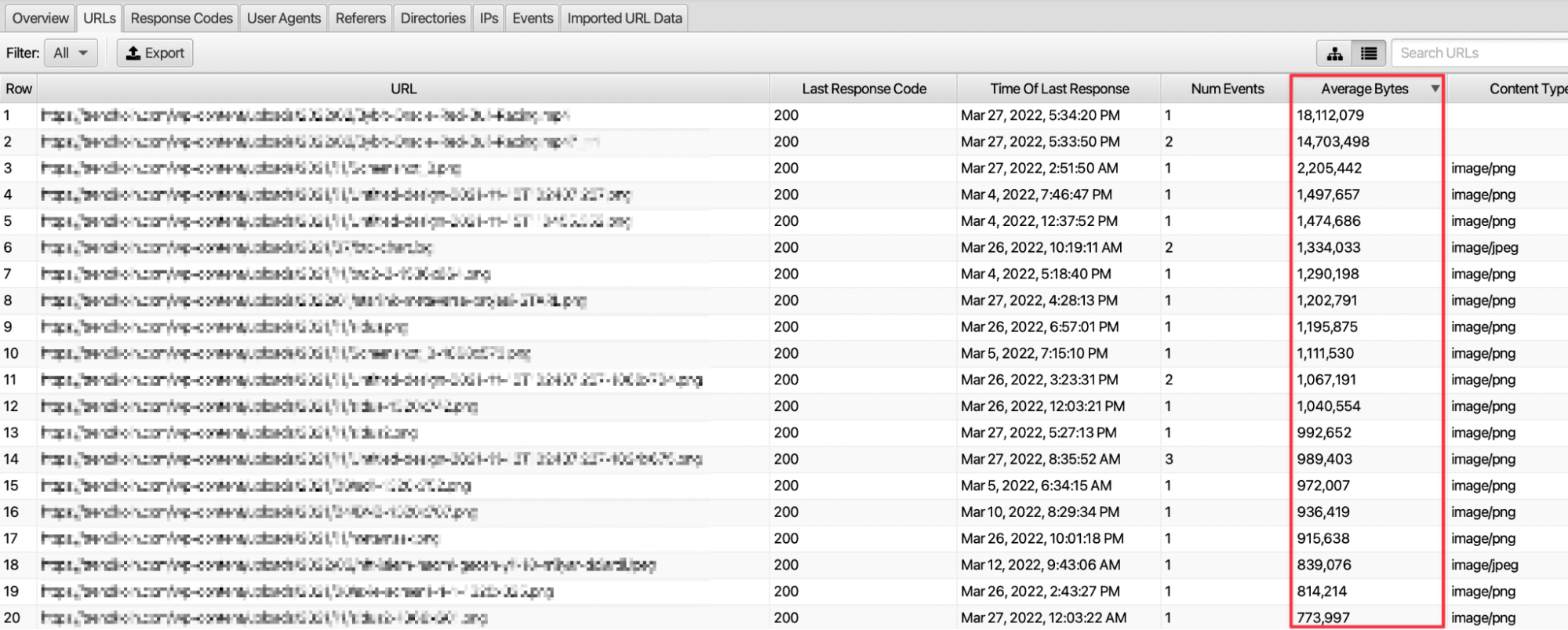
We can access the size of the resource from the Average Bytes column in the URLs section. Frequent crawling of high-dimensional resources such as JS and images can cause inefficient use of the budget. Here, we should optimize for pages with high request frequency and high size as much as possible.
7. Scanning Frequency by File Type
URLs on a website can be a page or a file type such as a resource or an image. For example, we can access information about the browsing frequency of the images on our site and which bots make more requests.
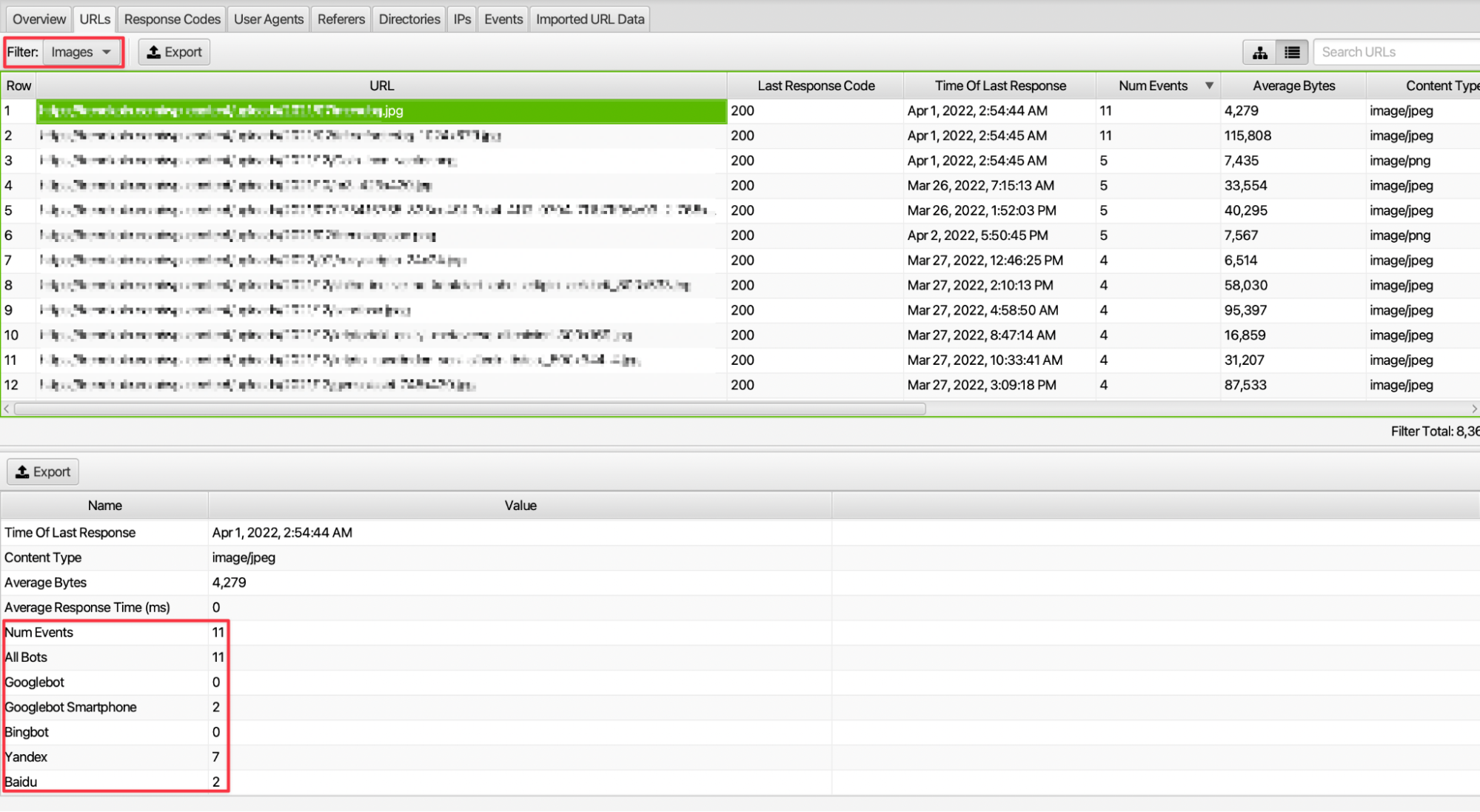
8. Examination of URL Paths with a Focus on 200 Status Codes
We can access the output of page types such as tag, pagination, and AMP on the website with the filtering feature. For example, we can access data on the number of requests to tag pages and the response code returned by this request, and the response rate with 200 response codes.
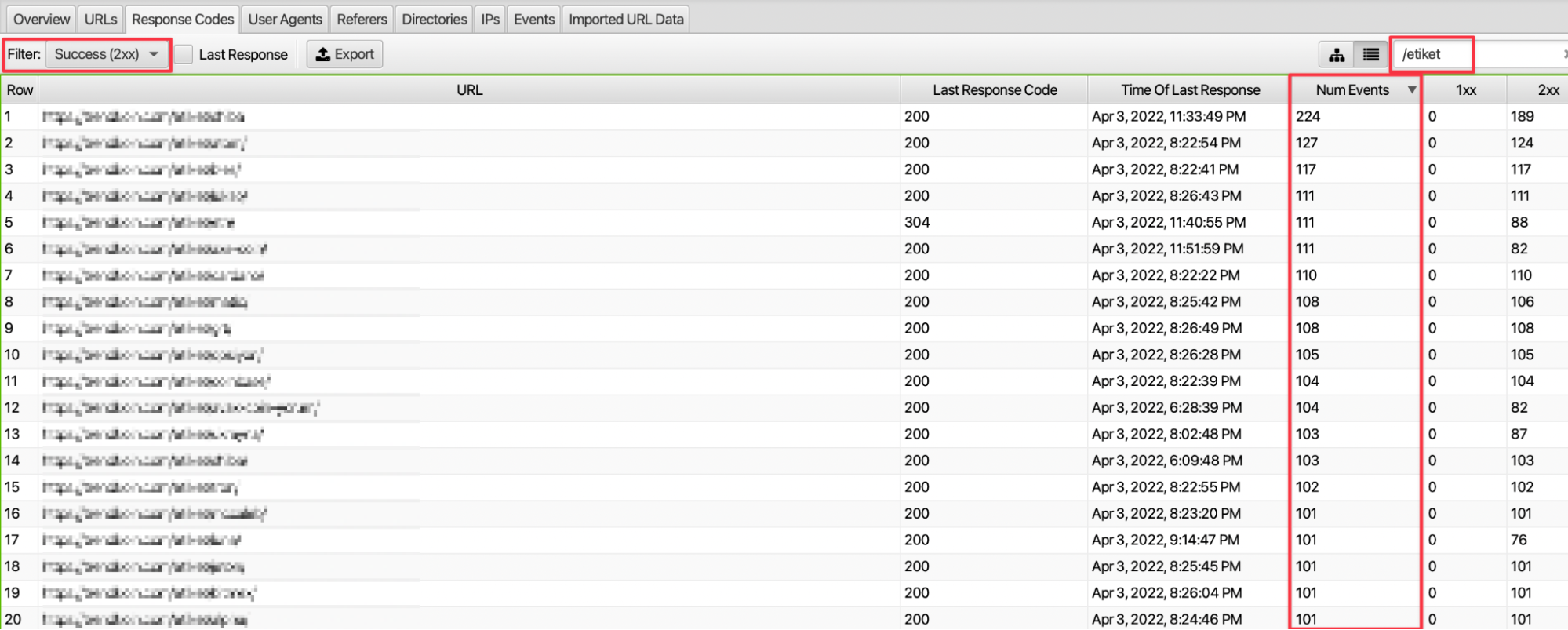
9. Review of Daily, Weekly, or Monthly Crawled URLs
We can examine the performance of the data in the log file of our website on a daily, weekly, monthly, or specific date range. For example, we can access outputs on the actions of crawlers by examining issues such as the frequency of user agents in the week of site migration, and the number of requests received in the relevant week.
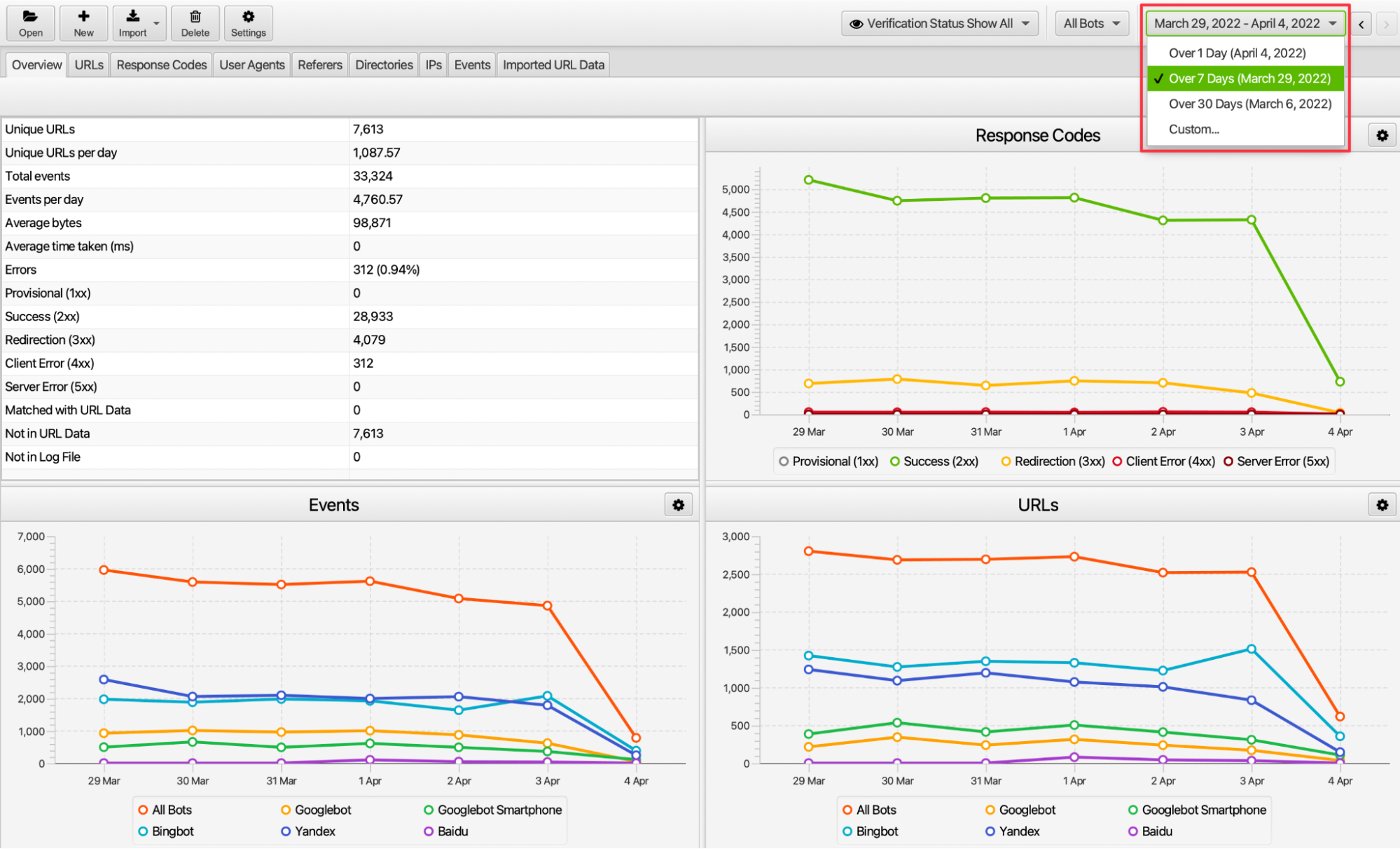
10. Server Request Review
In the overview section of the Screaming Frog Log Analyzer, we can examine the status code, especially in the case of redirects, not opening, or encountering server problems. With the filtering here, we can see whether the server-focused incoming requests are problematic or not.
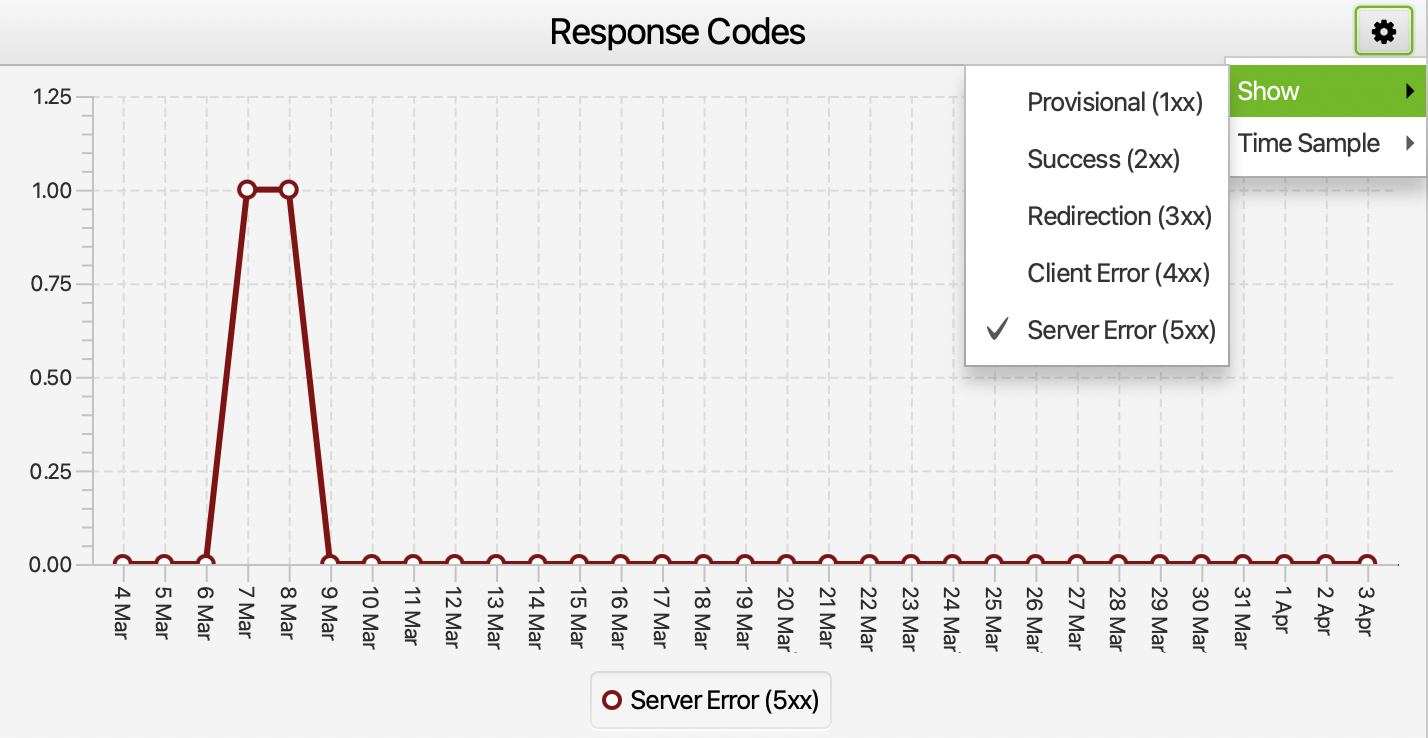
If there are requests that cause serious server problems on some days, we can access information on which pages this problem occurs in the last response code section in the URLs tab. We can present this information to the server provider and find out why if there is a problem here.
In summary, we can take meaningful actions by analyzing the requests coming to our website. With these actions, we can use the crawling budget efficiently and ensure that the pages we want to get traffic are crawled more effectively.



















