


Log Analizi Nedir? Screaming Frog ile Log Analizinin Püf Noktaları
Log analizi teknik SEO odağında ileri düzey aksiyonları içeren maddelerin başında gelmektedir. Bu yüzden internet sitemize dair fırsatları ve mevcut yapının iyileştirilmesi için oldukça önemlidir. Ancak log analizi sonucunda elde edilen çıktıları nasıl anlamlandırılacağı hususu kritiktir. Çünkü log analizinde tüm veriler her zaman istenilen çıktıyı veya aksiyon odağında bir veri sunmayabilir.
Log Dosyası Nedir?
Log dosyası internet sitesine istek gönderen tüm kaynaklara dair aksiyonların birlikte tutulduğu veridir. Bu veri günlük tutularak, bir zaman periyoduna dair analizlere de olanak sağlayabilmektedir. Sunucuda saklanan log dosyası, bazen sunucu sağlayıcıları tarafından aktif olmayabilir. İnternet sitesi sahibi olarak sunucu sağlayıcınıza log dosyasının akibiyeti hakkında bilgi almakta fayda bulunmaktadır.
Log dosyası kendi içerisinde bazı bilgileri bulundurmalıdır. Bunlar; IP adresi, tarih, istek türü, yanıt kodu, isteği yapan kaynak bilgisi, sayfa ve isteği atan adresin bilgisidir.
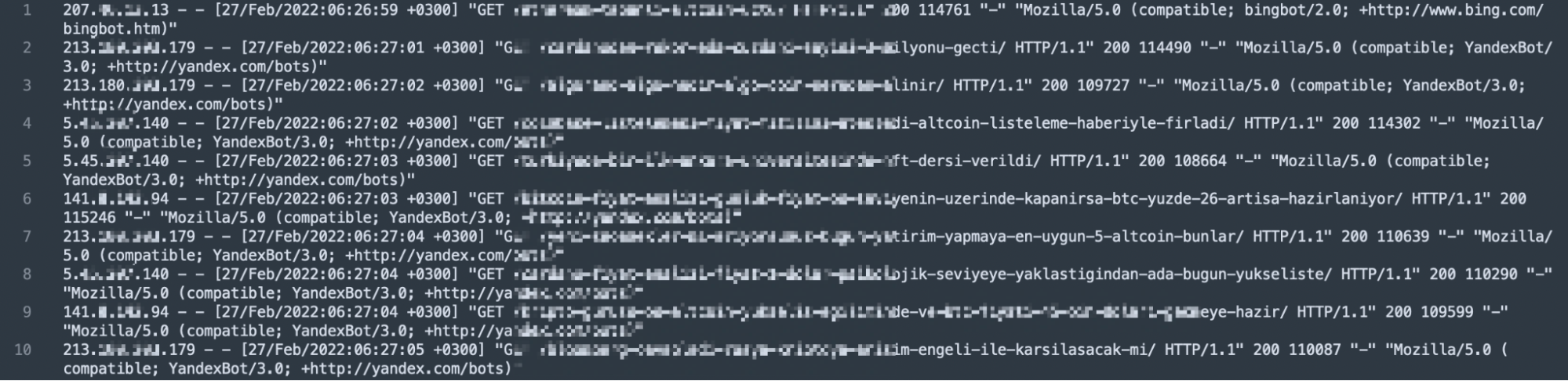
Bu bilgiler ışığında örnek log kaydının 123.45.67.67 - - [27/Feb/2022:22:26:49 +0300] "GET /log-analizi-nasil-yapilir/ HTTP/1.1" 200 115387 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" yapısında tutulduğunu düşünebiliriz.
Log Analizi Nedir?
Log analizi, arama motoru örümceklerinin internet sitenize göndermiş oldukları isteklere dair bilgi sunar. Bu bilgi, sitenin ne kadar tarandığı, hangi botların daha fazla ziyaret ettiği, istek sonucu sayfanın hangi yanıt kodu ile karşılık verdiği gibi hususlar sayesinde analiz imkanı sağlamaktadır. Bu bilgiler sayesinde varsayım yerine veriye dayalı olarak aksiyon ve analiz fırsatına sahip olabilmekteyiz. Geçtiğimiz aylarda sunduğumuz SEO için log analizini kullanmaya dair kapsamlı bilgilere ve video içeriğe buradan erişebilirsiniz. 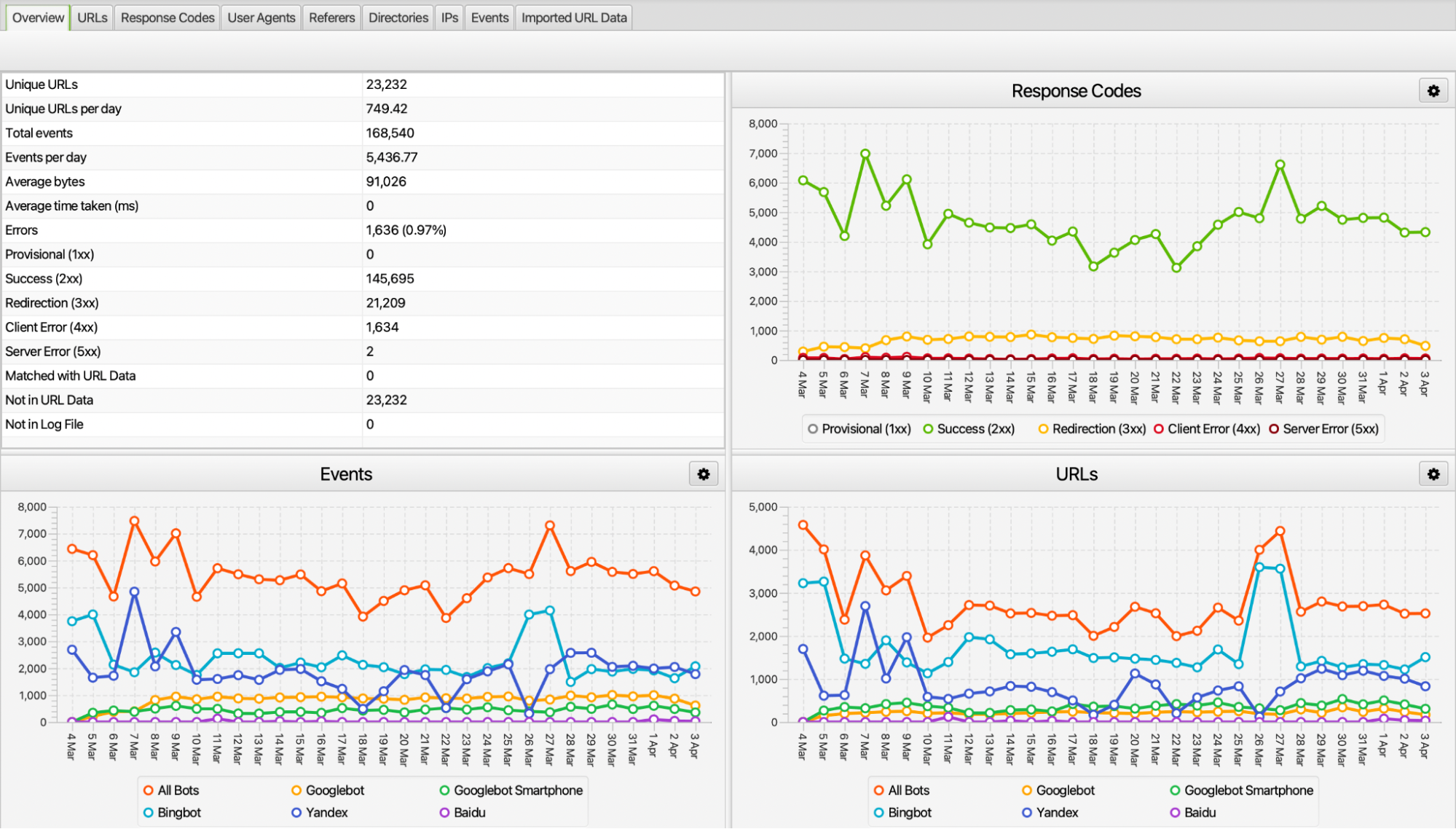
Log analizi gerçekleştirirken dosyaların günlük analizini yaparak ayrıntılı incelemeler gerçekleştirebilirsiniz. Bu incelemeler sonucunda aşağıdaki gibi bazı çıktılara erişebilmekteyiz.
- Hangi sayfa veya dosya yapısının sıklıkla taranıp taranmadığı bilgisi.
- Sayfaya gelen istek sonucunda hangi yanıt veya hata kodu döndürdüğü.
- Taranabilirlik kontrolleri.
- Tarama bütçesi optimizasyonu.
- Crawler’ların hangi sayfalara daha fazla istek atarak önem düzeyi bilgisi.
Tarama Bütçesi Nedir?
Tarama bütçesi arama motoru botlarının siteyi taramak için almış olduğu aksiyon ile birlikte dizine eklediği sayfaları tekrar tarayabildiği durumda geçirdiği süreyi ifade etmektedir. Bu yüzden her sitenin tarama bütçesi birbiri ile aynı değildir.
Kısaca botların internet sitesinde tarayabildiği URL sayısı için ayırdığı eforu ifade etmektedir. Burada eforun azaltılmasını da tarama bütçesi optimizasyonu olarak adlandırabiliriz. Çünkü sitede bulunan ve hedeflemediğimiz sayfaların taranmaması, internet sitesi için ayrılan tarama bütçesinin verimli kullanılmasını sağlayacaktır.
Screaming Frog Log Analyser ile Log Analizinin 10 Püf Noktası
Screaming Frog Log Analyser aracı içerisinde birçok kısım ve verilerin farklı hususlarda analizini sunmaktadır. Özellikle genel bakış kısmında crawler’ların istek sayıları, kaç adet URL’e istek gönderdiği, hangi durum koduna sahip olduğu ve benzersiz URL sayısı gibi bilgilere erişebilmekteyiz. Aslında bu veriler dışındaki kısımların analizini yapabilmek de oldukça kıymetli.
1. User Agent İsteklerinin İncelenmesi
İnternet sitesine Googlebot, YandexBot, bingbot, baidu gibi birçok crawler’dan istek gelmektedir. Bu isteklerin ise daha çok internet sitemizin kullanıcıları tarafından tercih edilen arama motorlarına ait crawler’lar olması gerekmektedir. Örneğin Bing tarayıcısından sitemize gelen kullanıcıların olmadığı veya çok az olduğu durumda, mevcut log incelemelerinizde bingbot’un çok fazla istek gönderdiği çıktısına sahipsek burada aksiyon alınması gerektiği çıkarımında bulunacağız.

Bingbot’un Crawl-delay değerini artırarak daha az gelmesini sağlayabilir veya robots.txt dosyasından bingbot’u taramaya kapatabiliriz. Bu sayede internet sitemize katkısı olmayan ve gereksiz istek gelen user-agent’ın tarama bütçesini harcamasının önüne geçmiş olduk.
2. Yanıt Kodu Kontrolleri
İnternet sitesinde bulunan URL’lere gelen istekler sonucunda sayfa bir yanıt kodu sunmaktadır. Bu yanıt kodları ise kendi içerisinde farklı bilgileri ifade etmektedir. Örneğin 500 yanıt kodu sunucu sorununu ifade ederken, 200 yanıt kodu sayfanın sorunsuz açıldığını belirtmektedir. Log analizinde yanıt koduna göre bazı çıkarımlarda bulunabiliriz. Örneğin yakın zamanda AMP sayfaları ana versiyonlarına 301 ile yönlendirdiğimizi varsayalım. Bu durumda /amp içeren sayfalarımıza gelen istek oldukça fazla olabilir.
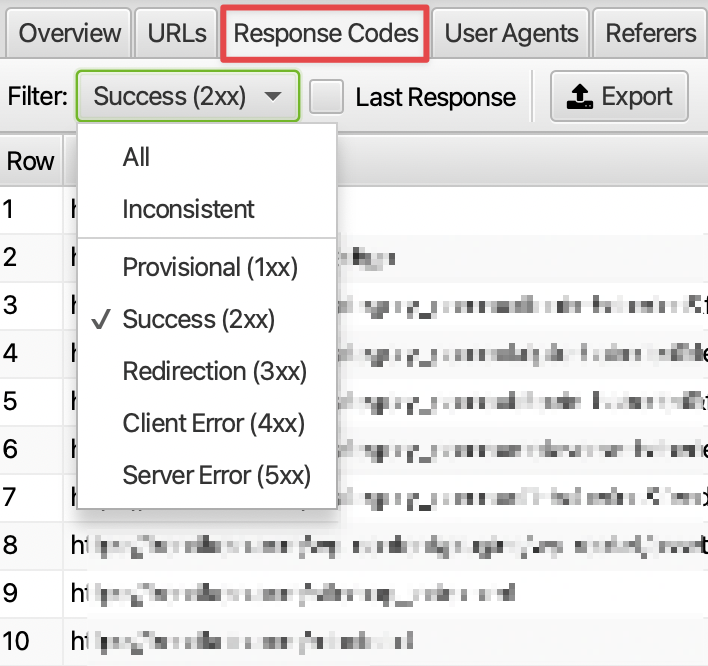
Bu URL’ler indekste bulunmuyorsa robots.txt dosyasından taramaya kapatarak gereksiz isteğin azalmasını sağlayabiliriz. Log çıktılarına göre farklı durumlar oluşabilir ve bu durumlara özel aksiyon alınması gerekmektedir.
3. İstek Sayılarının İncelenmesi
Crawler’ların en çok ve en az istek gönderdiği sayfalarımızı tespit edebiliriz. Özellikle kaynak filtrelemesi ile birlikte sadece HTML veya görselleri inceleyip ilgili tarih aralığında toplam kaç adet istek gerçekleştiği bilgisine erişebiliriz.
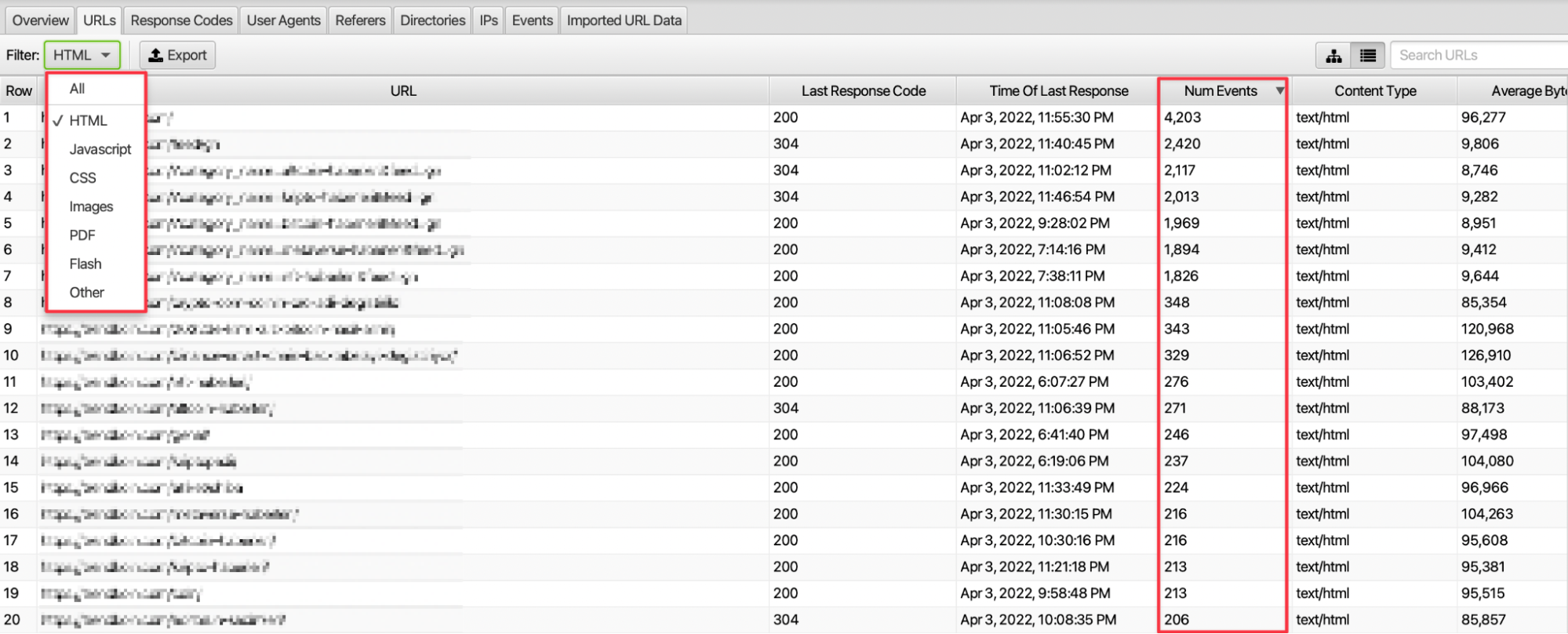
İstek sayılarını inceleyerek hangi türde kaynaklara arama motoru örümceklerinin daha fazla tarama isteği attığı bilgisini görebiliriz.
4. Sayfaların Tarama Sıklığının İncelenmesi
Sayfalarımızın crawler’lar tarafından tarama sıklığına user-agent ve durum kodu özelinde bakabiliriz. Bu sayfalara hangi botlardan daha fazla istek geldiğini de URLs ekranını sağa doğru kaydırınca görebiliriz. Aynı zamanda Response Codes kısmında ilgili URL’lere gelen isteklerde hangi yanıt kodu ile karşılaşıldığı bilgisi de bulunmaktadır.
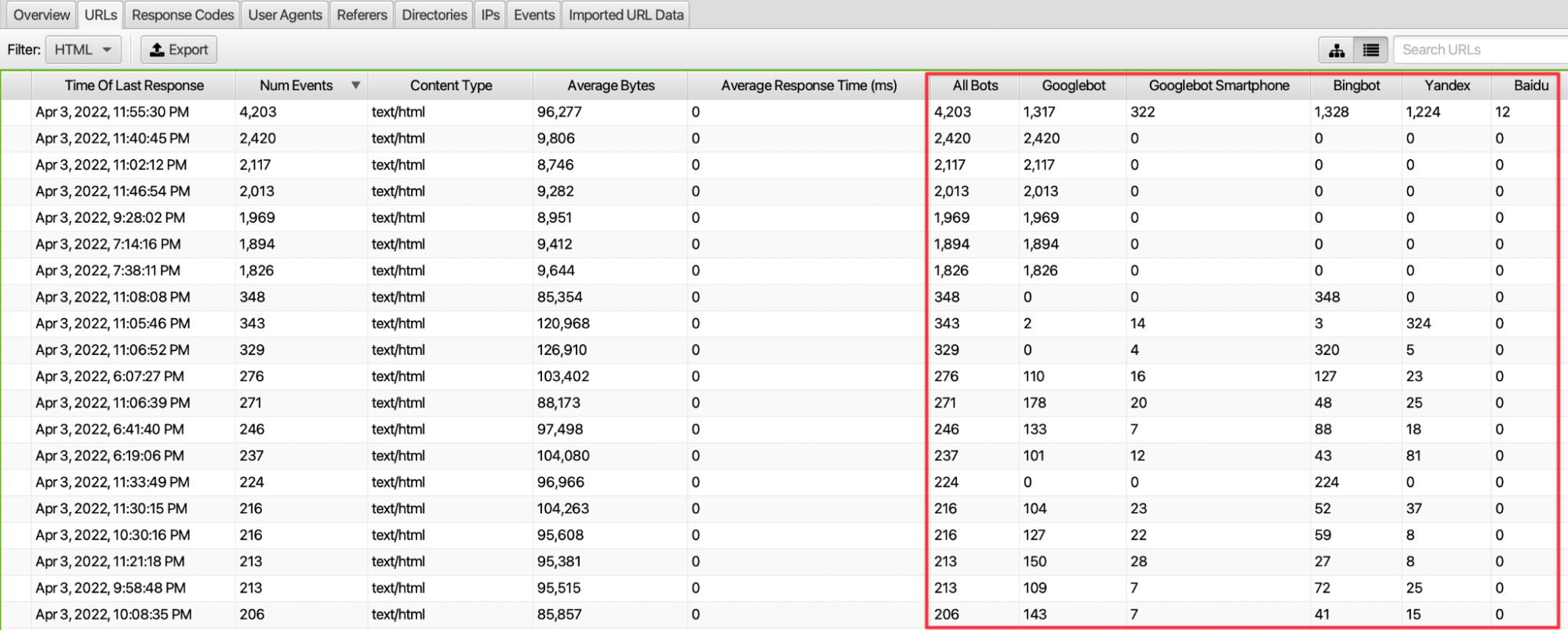
Özellikle ilgili tarih aralığında internet sitesine gelen istek sayısının URL sayısına bölümü ile sayfalarımıza gelen ortalama istek verisine erişebiliriz. Bu veri ile diğer sayfalarımıza gelen istek sayısını karşılaştırarak crawler’ların bazı sayfalarımıza yaklaşımlarına dair çıkarımda bulunabiliriz. Ciddi isteği bulunan ancak crawler özelinde gereksiz görülen sayfalar varsa ilgili crawler’ın taramasına kapatarak aksiyon alabiliriz.
5. Directory/Subfolder Özelinde Crawler’ların Tarama Sıklığı
İnternet sitesinin URL yapısında bulunan subfolder yapısının tarama sıklığını görebilmek için Directories sekmesinde yer alan verileri inceleyebiliriz. Burada subfolder yapısının kategori veya belli bir kırılımı ifade ettiğini düşünürsek internet sitemizde hangi kısımların daha fazla ziyaret edildiği çıkarımında bulunabiliriz.
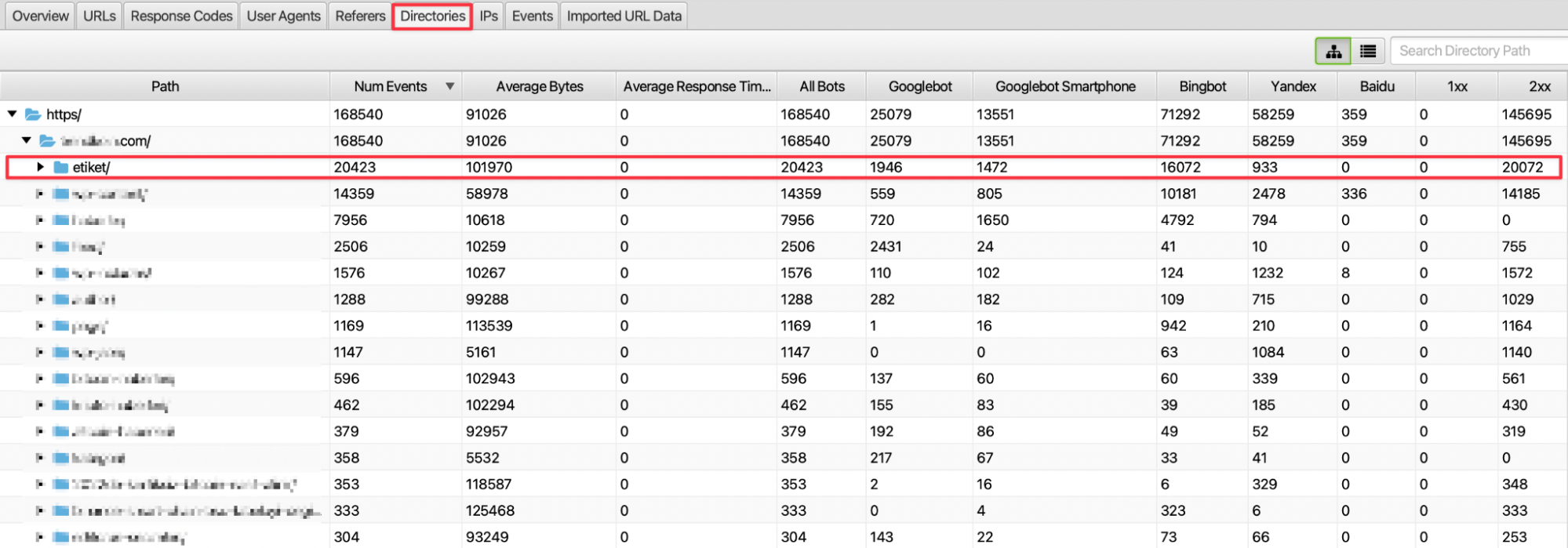
Örneğin yukarıdaki görselde etiket sayfalarına diğer subfolder yapılarından daha fazla istek geldiği ve bu isteğin ciddi bir kısmının Bingbot’un taramasıyla oluştuğu görülüyor. Bu durumda subfolder yapısında crawler’lar için inceleme gerçekleştirebiliriz. Tespit ettiğimiz subfolder yapılarından ise diğer alakalı kategori veya sayfalarımıza site içi linkleme stratejisi geliştirebiliriz. Bu sayede crawler’ları diğer alakalı sayfalarımıza yönlendirip daha etkin bir tarama gerçekleştirmiş oluruz.
6. Yüksek Boyutlu Kaynakların Tespiti
Crawler’ların internet sitesine ayırmış olduğu tarama bütçesini verimli kullanabilmek adına kaynaklarımızın boyutlarını kontrol etmeliyiz. Yüksek boyutlu olan kaynaklarda optimizasyon yaparak tarama bütçesinde etkin kullanımı sağlayabiliriz.
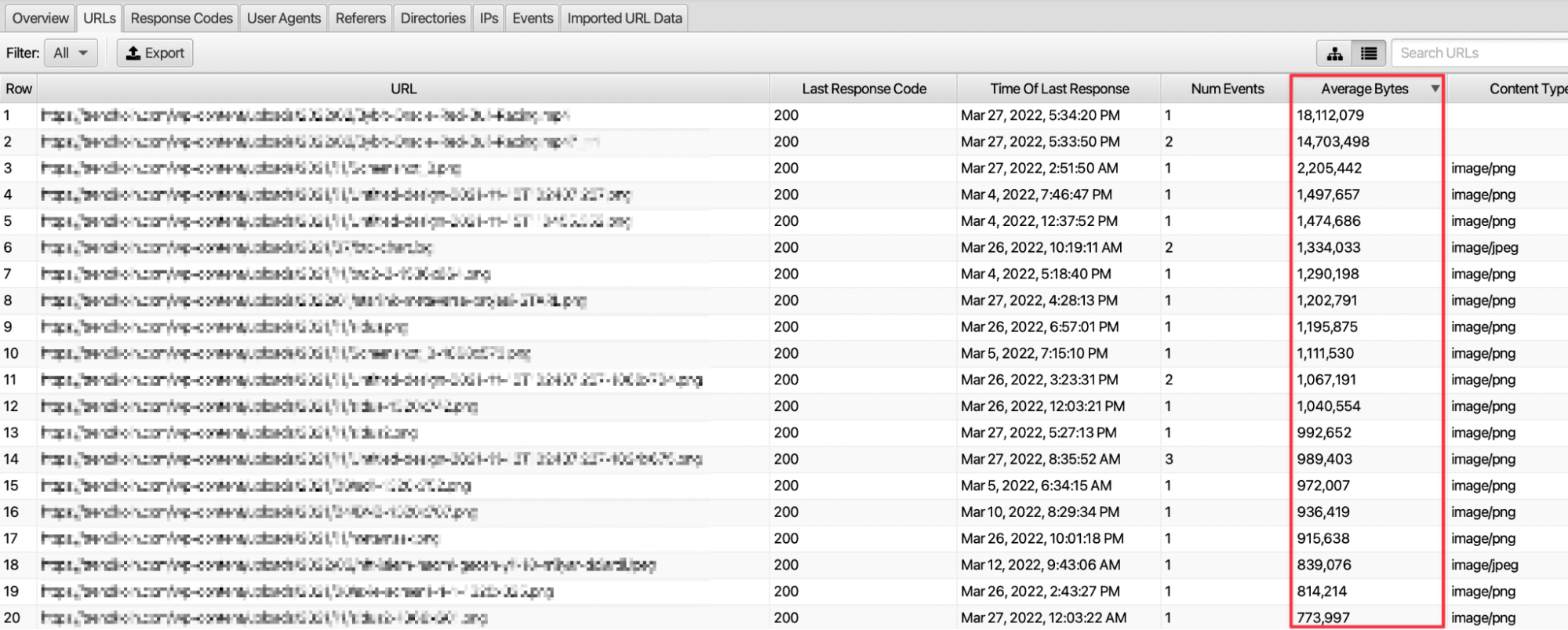
URLs kısmındaki Average Bytes sütunundan kaynağın boyutuna erişebiliriz. Özellikle JS, görsel gibi yüksek boyutlu kaynakların sıklıkla taranması bütçenin verimsiz kullanılmasına neden olabilmektedir. Burada mümkün olduğunca istek sıklığı bulunan ve yüksek boyutlu sayfalarda optimizasyon yapmalıyız.
7. Dosya Türüne Göre Tarama Sıklığı
İnternet sitesinde bulunan URL’ler bir sayfa olabileceği gibi, kaynak veya görsel gibi dosya türlerini de barındırmaktadır. Örneğin sitemizde bulunan görsellerin tarama sıklığı ve hangi botlar tarafından daha fazla istek geldiği bilgisine erişebiliriz.
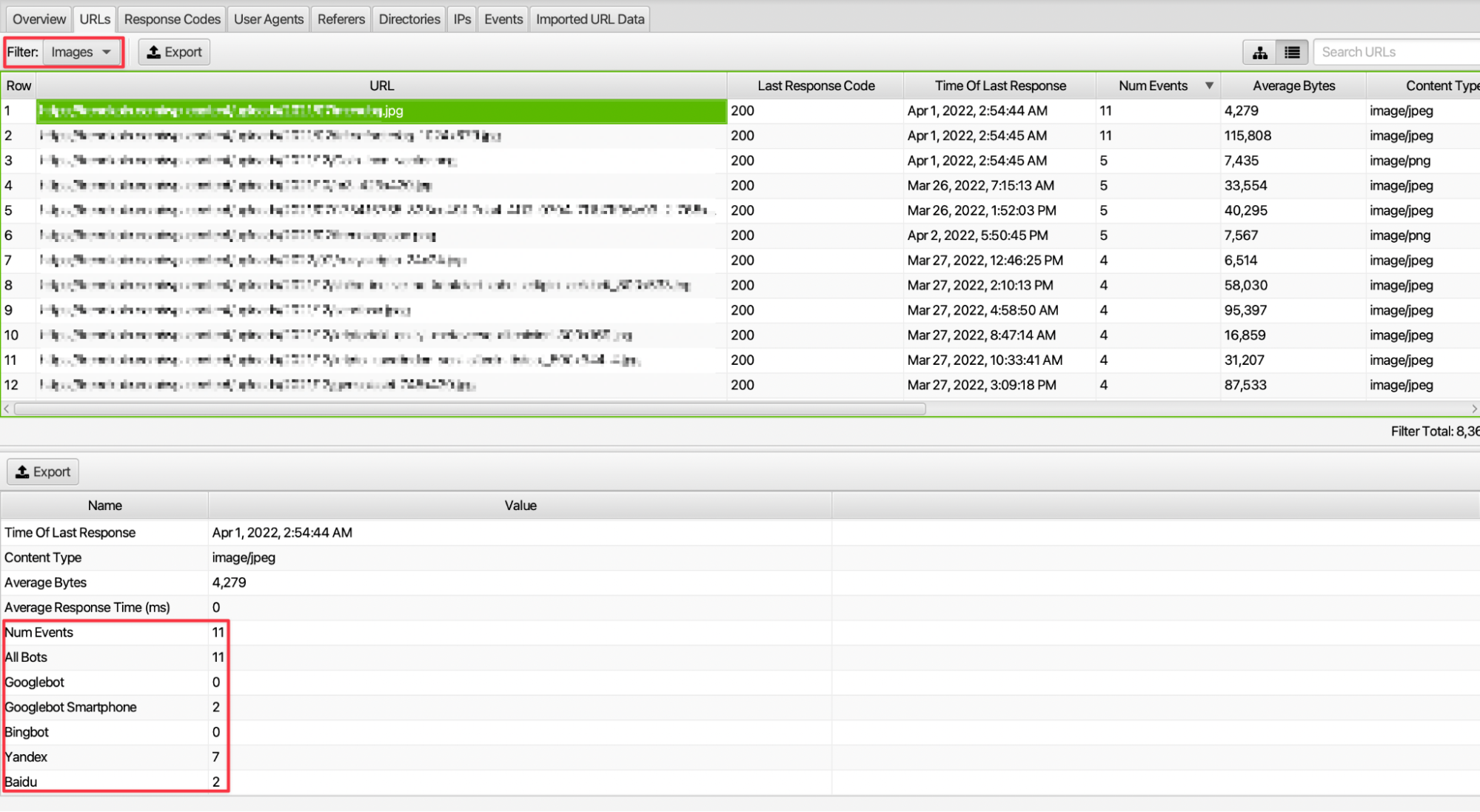
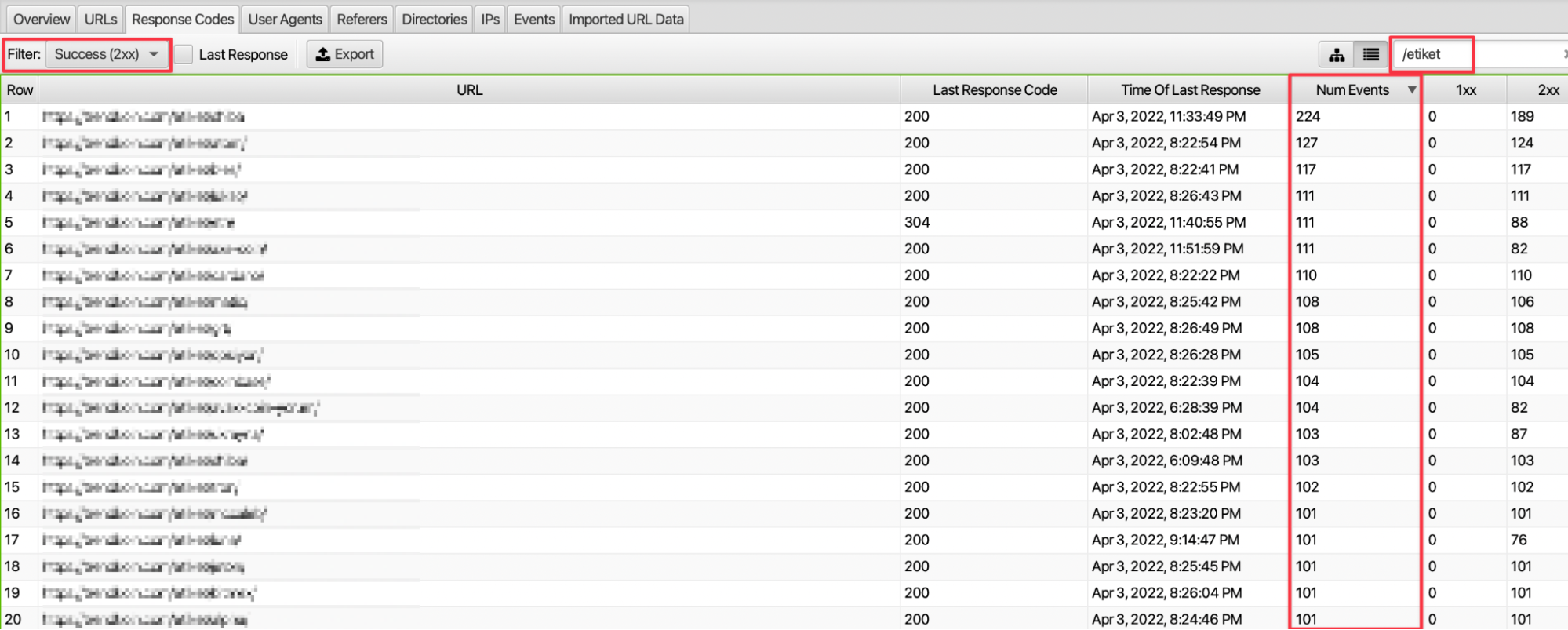
8. 200 Durum Kodu Odağında URL Path’lerinin İncelenmesi
İnternet sitesinde bulunan etiket, pagination, AMP gibi sayfa tiplerine dair çıktılara filtreleme özelliği ile erişebilmekteyiz. Örneğin etiket sayfalarına gelen istek sayısına ve bu isteğin hangi yanıt kodu döndürdüğüne, 200 yanıt kodu ile karşılama oranına dair veriye ulaşıyoruz.
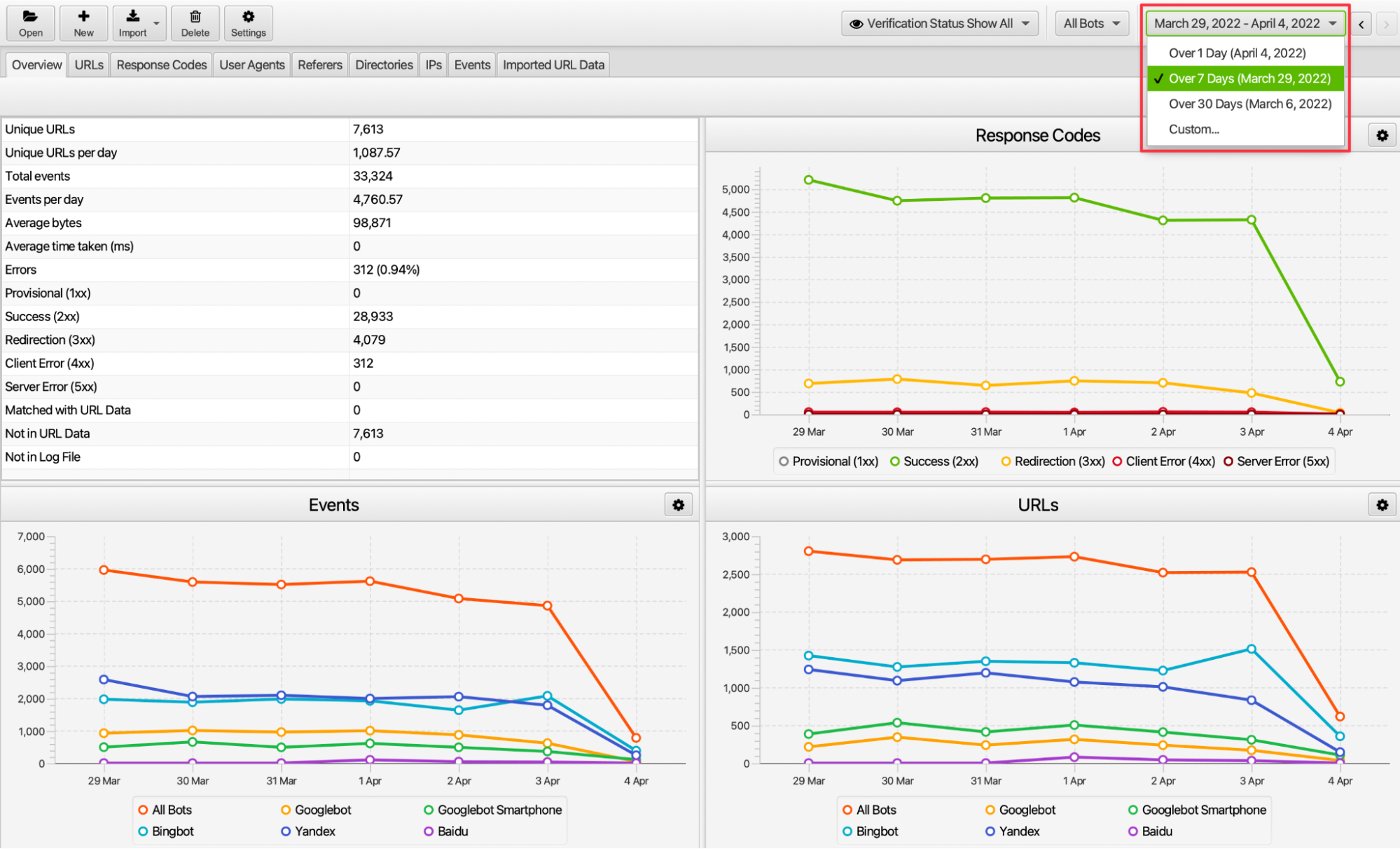
9. Günlük, Haftalık veya Aylık Taranan URL'lerin İncelenmesi
İnternet sitemize ait log dosyasındaki verilerin günlük, haftalık, aylık veya belli bir tarih aralığındaki performansını inceleyebiliriz. Örneğin site geçişi yapılan haftada user agent sıklığı, ilgili haftada gelen istek sayısı gibi hususları inceleyerek crawler’ların aksiyonlarına dair çıktılara erişebiliriz.
10. Sunucu İsteğinin İncelenmesi
Screaming Frog Log Analyzer’ın genel bakış kısmında durum kodu olarak özellikle yönlendirme, açılmayan veya sunucu sorunu ile karşılaşma durumlarını inceleyebiliriz. Sunucu odağında gelen isteklerin sorunsuz olup olmadığını buradaki filtreleme ile görebiliriz.
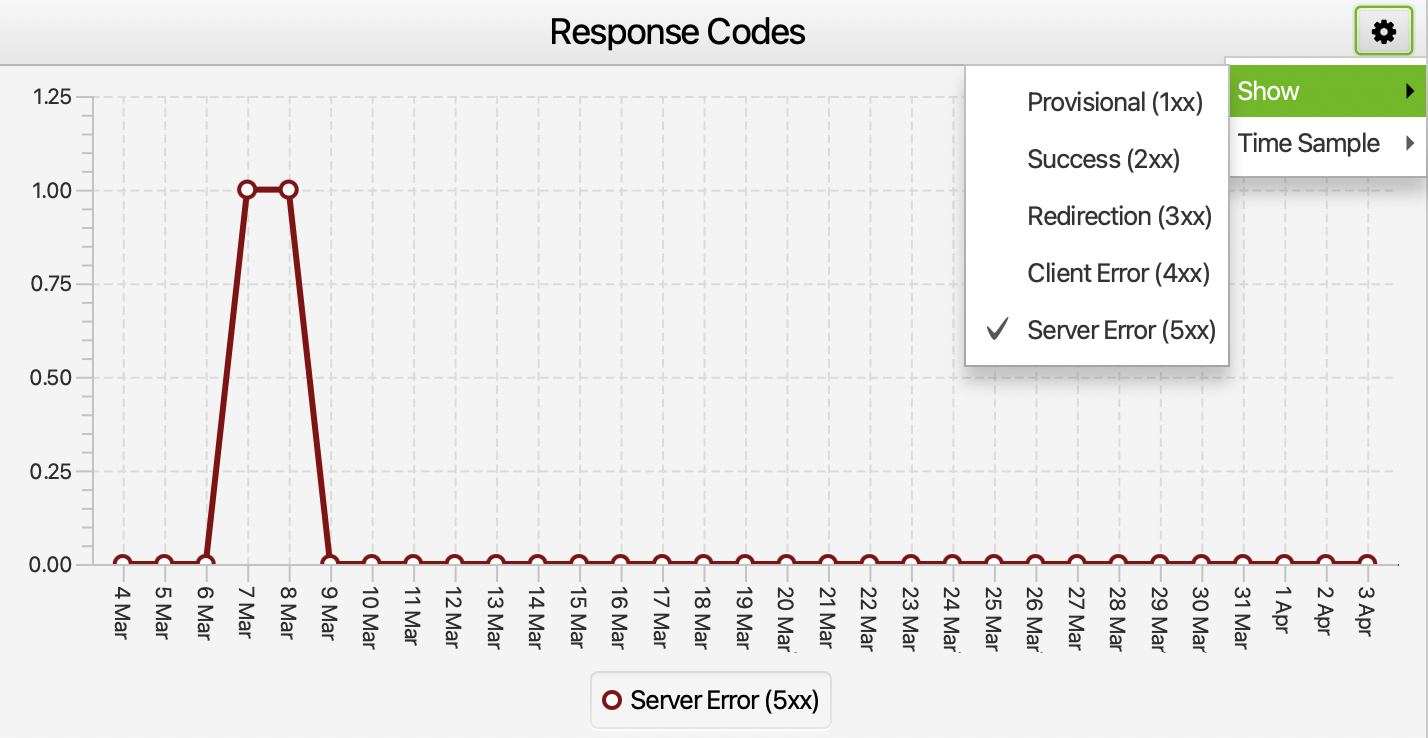
Eğer bazı günlerde ciddi oranda server sorunu oluşturan istek varsa URLs sekmesinde last response code kısmından hangi sayfalarda bu sorunun oluştuğu bilgisine erişebiliyoruz. Bu bilgiyi sunucu sağlayıcı firmaya sunup burada sorun bulunuyorsa nedenini öğrenebiliriz.
Özetle, internet sitemize gelen isteklere dair incelemeler ile anlamlı aksiyonlar alabiliriz. Bu aksiyonlar ile tarama bütçesini verimli kullanarak trafik elde etmek istediğimiz sayfaların daha etkin taranmasını sağlayabiliriz.



















