


R Studio'da ChatGPT Kullanımı ve Bilinmesi Gerekenler
İstatistik ve veri analizlerinde R çok fazla kullanılıyor. Peki ChatGPT’yi R’da nasıl kullanabilirsiniz? Bu yazım istatiksel analiz yapmak isteyenleri ve R sevenleri daha çok ilgilendirecektir.
R Project ve R studio kurulumlarını başka bir yazımda anlatmıştım, henüz kurulum yapmadıysanız ilgili makaleyi okuyabilirsiniz. Ayrıca R & SEO ile ilgili diğer yazılarıma da yine Zeo Blog’tan ulaşabilirsiniz.
ChatGPT’yi R’da Çalıştırma & API Kurulumu
ChatGPT’ye R üzerinden bağlanmak için öncelikle https://platform.openai.com/account/api-keys adresinde API oluşturmanız gerekiyor. Key’e isim verip kaydedelim ve bu kodu mutlaka bir yerde saklayalım:
R’a geri dönüp ilk kodlarımızı çalıştırıyoruz ve kütüphaneleri kuruyoruz:
library("TheOpenAIR")
API Key bilgilerimizi de R içine ekliyoruz:
library("TheOpenAIR")
openai_api_key("sk-apı_key")
Kütüphanenin aşağıdaki gibi kurulması gerekiyor. Ayrıca ("dplyr") kurulu değilse aşağıdaki bu paketi de kurabilirsiniz:

Örnek Paketler ve Kullanımlar
Paketimiz kuruldu ve artık OpenAI ile bağlantımız var. Geriye sadece istediğimiz promptu girmek kalıyor:
chat("R Studio'nun SEO'da nasıl kullanılabileceği ile ilgili 175 karakterlik meta description yaz.")

Bundan sonrası aslında ChatGPT’den ne istediğimize bağlı olarak şekillenmeye başlayacak. Örneğin “model” ile gpt-3.5-turbo ile seçim yapabilirim. İsterseniz GPT-4 de kullanabilirsiniz. “temperature” değeri ile istediğiniz değeri belirtip en iyi sonuçlar almak için uğraşabilirsiniz:
chat("150 kelimelik R Studio'yu anlatan kısa bir tanıtım metni yaz",
model="gpt-3.5-turbo",
temperature=0.8)

frequency_penalty ile frekans sıklığını belirtebilirsiniz: (Ek bilgi)
chat("150 kelimelik R Studio'yu anlatan kısa bir tanıtım metni yaz",
model="gpt-3.5-turbo",
frequency_penalty=1,
temperature=0.8)

Ayrıca “count_tokens” ile örneğin bir URL’deki token sayısını okuyabilirsiniz:
url <- "https://zeo.org/tr/kaynaklar/blog/chatgpt-anahtar-kelime-analizi-ve-google-sheets-otomasyonu"
count_tokens(url)

Farklı neler yapılabileceğini projeleriniz ya da işlerinize göre daha detaylandırabilirsiniz. Ben durumu özet haline getirmek için bu örnekleri veriyorum. Örneğin FAQ alanları için buradan yardım alabilirsiniz:

Örnek bir data.frame oluşturmak ve bunu görselleştirmek istiyorum. Net bir prompt yazıyorum:
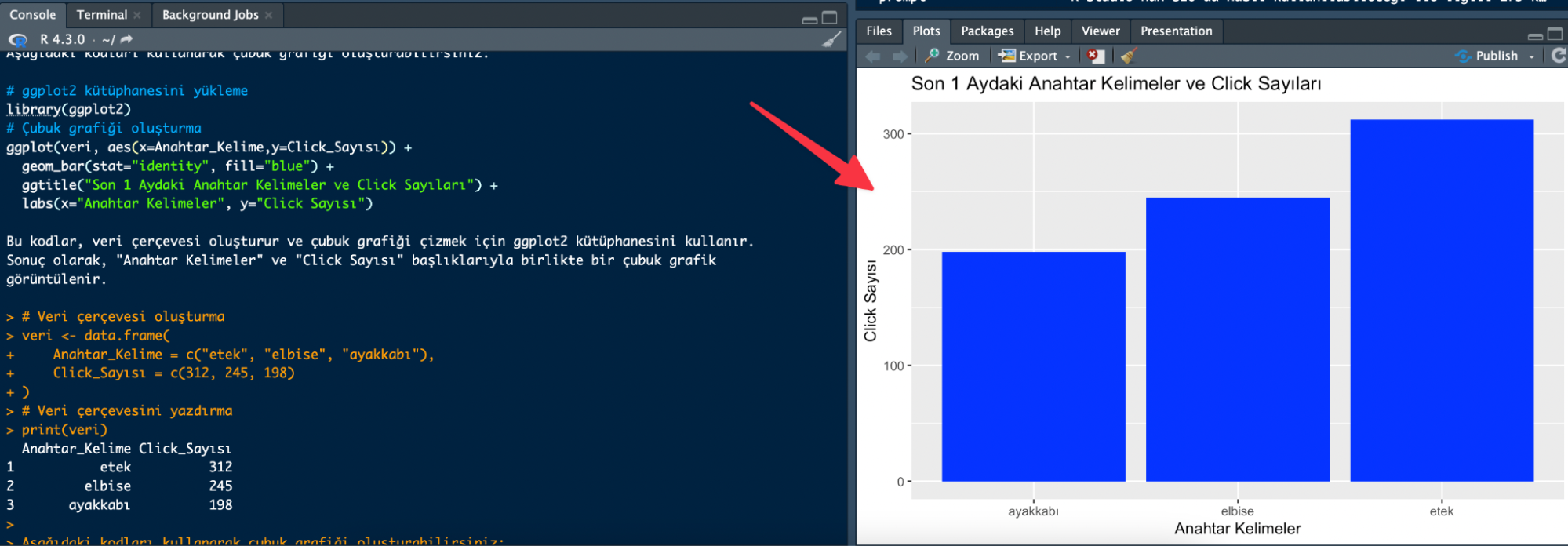
chat("Bir E-ticaret sitesine son 1 ayda ziyaretçilerin hangi anahtar kelimeleri kullanarak giriş yaptığını ve kaç click aldıklarını bir örnekle veri çerçevesi içinde bir data.frame olarak göster. Ardından çubuk grafiği oluştur ve hangi kodlar ile bunu yaptığını bana göster.",
model="gpt-3.5-turbo")

Çıktı direkt adım adım bu işlemi nasıl yapacağımı anlatıyor:

Sonuç olarak istediğim grafiği oluşturdum. Bir .csv ya da .txt dosyasını nasıl R’a import edebileceğini hatta URL’leri nasıl tarayabileceğinizi başka yazılarımda anlattığım için bu detaylara girmiyorum:
Ayrıca ChatGPT’den aldığınız cevabı tek satırda bir vektör haline getirebilirsiniz. Ardından bu vektöre istediğiniz tüm soruları sorabilir ya da istatiksel analizlerinizi gerçekleştirebilirsiniz. View komutu da zaten oluşturduğunuz bu veri setini görüntülemek için kullanabileceğiniz bir komut:
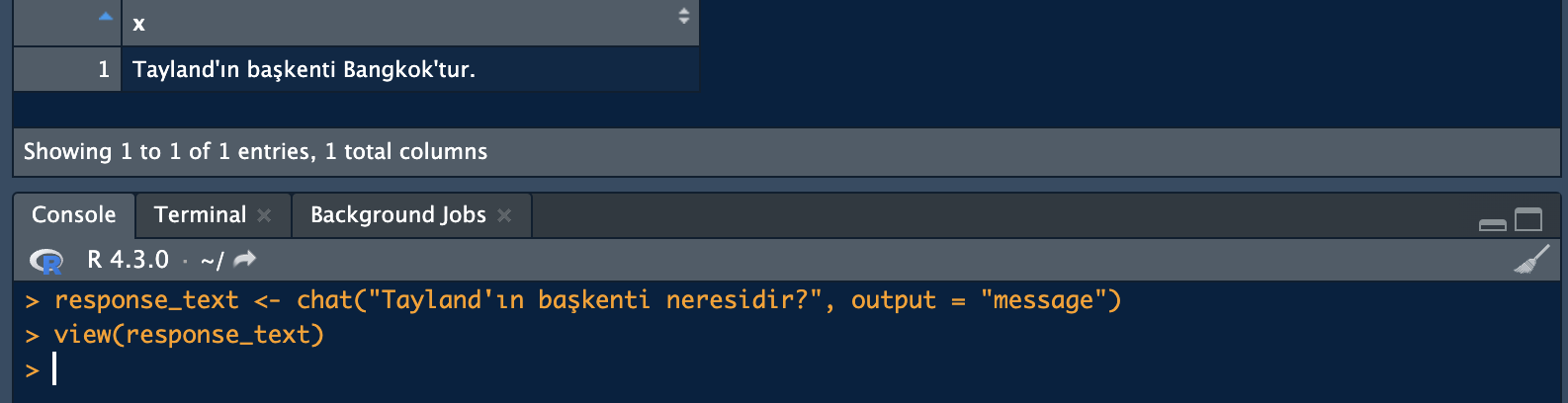
response_text <- chat("Tayland'ın başkenti neresidir?", output = "message")
view(response_text)
Örneğin bu yanıtı noktalara göre bölerek bir cümle listesi elde edebilirsiniz.

cumleler <- strsplit(response_text, "\\.")[[1]]
print(cumleler)
Yine bir makale yazmasını ve bu makalede geçen cümlelere göre word cloud oluşturmasını istiyorum:
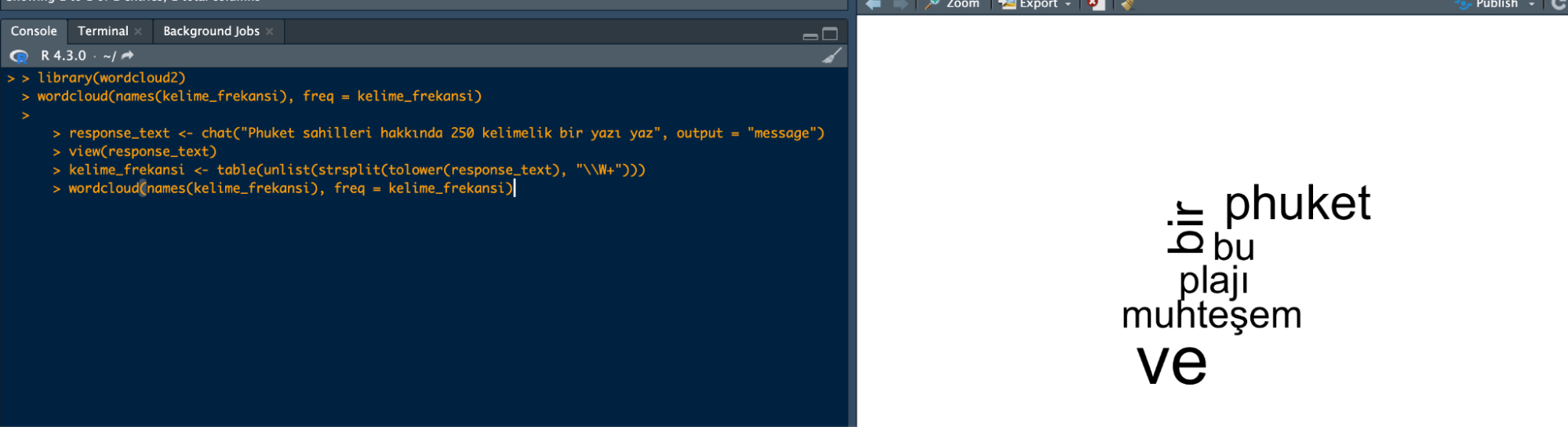
library(wordcloud2)
wordcloud(names(kelime_frekansi), freq = kelime_frekansi)
response_text <- chat("Phuket sahilleri hakkında 250 kelimelik bir yazı yaz", output = "message")
view(response_text)
kelime_frekansi <- table(unlist(strsplit(tolower(response_text), "\\W+")))
wordcloud(names(kelime_frekansi), freq = kelime_frekansi)
Bir yazıdaki öznel yargıları ise aşağıdaki gibi bulabilirsiniz. “grep” kısmından sonrakileri siz belirleyebilirsiniz, ben örnek olması için yazdım:

oznel_yargilar <- grep("ünlüdür|harika|güzel", tolower(response_text), value = TRUE)
oznel_yargi_sayisi <- length(oznel_yargilar)
print(oznel_yargi_sayisi)
ChatGPT’ye 2 adet aynı konuda yazı oluşturmasını istedim. Ardından jaccard benzerliğini kullanarak metinler arasında ortak kelimeler var mı bunu analiz etmek istedim. Burada hiç ortak metin çıkmadığını bana gösterdi:
library(stringdist)
jaccard_benzerlik <- stringdist::stringdist(metin1, metin2, method = "jaccard")
print(jaccard_benzerlik)

Jaccard benzerlik ölçeği 0 çıkması, iki metin arasında hiç ortak kelimenin olmadığını veya tüm kelimelerin farklı olduğunu gösterir. Bu durumda, Jaccard benzerliği 0 olarak yorumlanabilir ve iki metin arasında benzerlik yoktur:
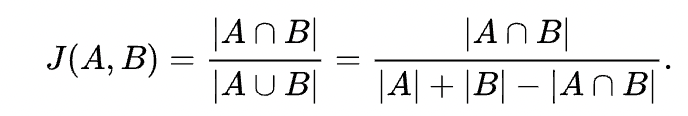
Yazımı buraya kadar okuyan herkese bol istatistikli ve AI ile işlerini olabildiğince kolaylaştırdığı günler dilerim.






















