


Google Analytics + R = Machine Learning
Daha önce Google Analytics verisinin Machine Learning algoritmaları ile kullanımına yönelik bir içerik olup olmadığı konusunda çokça araştırma yaptım. Fakat Analytics verisi üzerinden özellikle dönüşümü hangi parametrelerin sağladığına dair Makine Öğrenmesi yöntemlerini kullanan bir içerik bulamadım.
Bu nedenle bu yazımda bu yöntemleri kullanarak Analytics verisi nasıl daha iyi analiz edilebilir ve içerisinden çıkarabileceğimiz iç görüler nelerdir gibi konulardan bahsetmeye çalışacağım. Google Analytics sitemizi ziyaret eden kullanıcıların davranışlarını takip edebilmemiz ve sitemizi onlar için daha kullanışlı hale getirebilmemiz için kullandığımız en önemli veriye yönelik araçlardan birisi. Analytics ile ayrıca hangi kaynaklardan ne kadar kullanıcıyı sitemize getirebildiğimize dair de bilgiler alabiliyoruz.
Google Analytics veriyi bize bir araya getirilmiş halde sunuyor (her bir kullanıcı davranışını liste halinde detaylı şekilde göremiyoruz) ve bu durum gelişmiş analizler gerçekleştirebilmemize engel oluyor. Kullanıcılarınızın hangi parametrelere göre dönüşüm gerçekleştirdiğini bilebilmek için makine öğrenmesi algoritmaları gibi daha gelişmiş yöntemler kullanmak gerekiyor. Üstelik bu yöntemler sayesinde sitemizi gelecekte ziyaret edecek kullanıcıların dönüşüm kanalına ne kadar yakın olduklarını büyük doğruluk payıyla tahmin edebilir ve onları dönüşüme ikna etmek için gerekli aksiyonları da alabiliriz.
Kullanacağımız Veri
Bu yazıda Google Analytics verisi ile en temel Makine Öğrenmesi algoritmasını kullanarak dönüşümde rolü en büyük olan parametrenin hangi parametre olduğunu ve diğer parametrelerin dönüşümü ne oranda etkilediğini bulacağız. Bu adımları temel programlama bilgilerine sahipseniz siz de uygulayabilirsiniz. Ben bu yazımda R programlama dilini kullanacağım. Eğer kullandığınız yazılım dilinde benim kullanacağıma benzer hazır paketler bulunuyorsa işiniz çok daha kolay olacaktır. Kullanacağımız veriyi Google Analytics’ten Kitle Sekmesinin Altındaki Kullanıcı Gezgini (User Explorer) raporundan indireceğiz. Bu raporda sitemizi ziyaret eden kullanıcıların Müşteri Kimliklerine göre kaç adet oturum gerçekleştirdikleri, ortalama oturum sürelerinin ne olduğu ve hemen çıkma oranları ile Hedef Dönüşüm Oranları yer alıyor. Ayrıca Kazanç ve Dönüşüm Sayısı gibi metrikler de yer alıyorlar fakat bu metrikleri bu analiz sırasında kullanmamıza gerek yok. Bir aylık bir zaman aralığı seçiyor ve 5000 satır gösterme seçeneğine tıklıyoruz. Daha sonra bu rapordaki veriyi Export seçeneğiyle indiriyoruz. Genelde bir programlama dilini kullanacaksak Analytics’ten veriyi bu şekilde indirmiyoruz. Fakat Client ID parametresi normal şartlarda API aracılığıyla alabildiğimiz bir parametre olmadığı için şimdilik verimizi bu şekilde almamızda bir sorun yok.
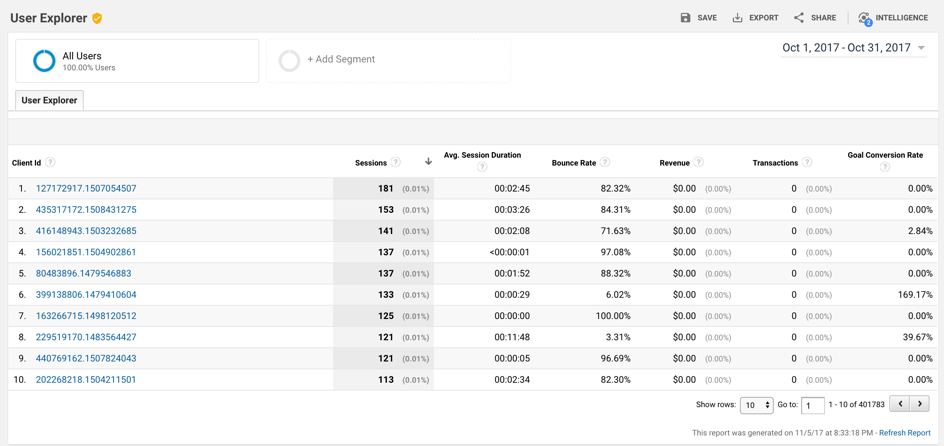
Makine Öğrenmesi (Machine Learning) ile Google Analytics Verisinin Analizi
Makine öğrenmesi algoritmaları arasında en temellerinden birisi olan Karar Ağaçlarını kullanacağız. Bu algoritmayı R içerisindeki rpart paketi ile kullanmak mümkün. Karar ağaçlarıyla verimizi farklı parametrelere göre gruplamamız mümkün hale geliyor. Örneğin eğer 1 dakikanın üzerinden oturum süresine sahip kullanıcılar dönüşüm gerçekleştiriyor fakat 30 saniyenin altında oturum sürelerine sahip kullanıcılar dönüşüm gerçekleştirmiyorlarsa ağacımızda bu yapı birbirinden ayrı bir şekilde gruplanabiliyor.
Rpart ile çalıştıracağımız karar ağacı bize girdi olarak vereceğimiz üç parametreyi de kullanarak bir model oluşturacak ve daha sonra oluşturduğumuz bu model üzerinden daha önce üzerinde herhangi bir inceleme gerçekleştirmediğimiz verilerde hangi kullanıcıların dönüşüm gerçekleştireceğini tahmin edeceğiz.
Veriyi bu şekilde ayırma mantığını training ve test setleri olarak ayırma şeklinde de görebilirsiniz. Training veri setimizde rpart ile modelimizi oluştururken, test setimizde modelimizin ne kadar yüksek başarıyla çalıştığını test ediyor ve eğer modelimiz beklediğimiz oranda başarılı değilse modelimizi geliştirmeye çalışabiliyoruz. 5000 satırlık verimizi R’da sample paketi ile rastgele 4500 tanesi bir değişkenin, 500 tanesi de başka bir değişkenin içerisinde olacak şekilde birbirlerinden ayırıyoruz.
- satiral <- sample(1:5000,500)
- test <- analytics_data[satiral,]
- training <- analytics_data [-satiral,]
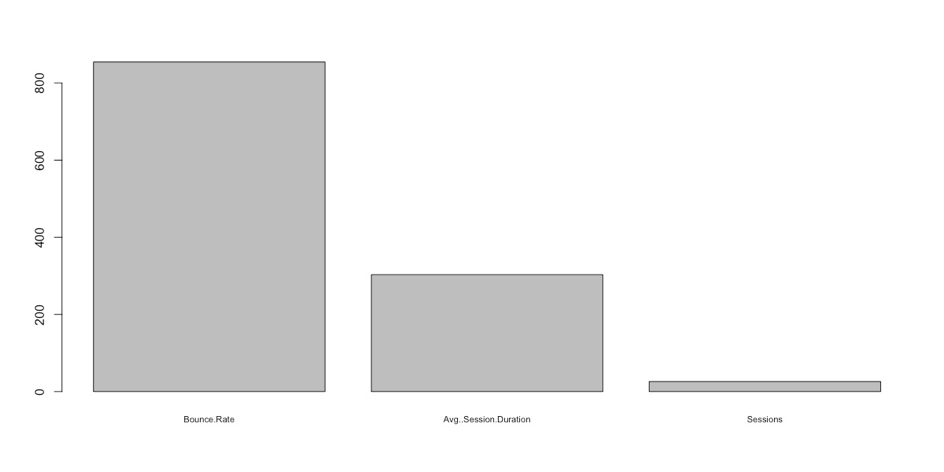
Daha sonra rpart fonksiyonunu çalıştırıyoruz ve oluşturulan fiti de bir değişkenin içerisine aktarıyoruz. Fitimizin parametreleri arasında modele göre hangi metriklerin dönüşümde daha çok pay sahibi olduğu bilgisi bulunuyor. Aşağıdaki grafiğe göre, Hemen Çıkma Oranı diğer metriklere göre çok daha büyük öneme sahip, ortalama oturum süresi de dönüşüm gerçekleştiren kullanıcıların ortak özellikleri arasında yer alıyor. Tabi herhangi bir web sitesi sahibine sorsaydık, hedef tamamlama gerçekleştiren kullanıcılarının Hemen Çıkma Oranının düşük olduğunu, Ortalama Oturum Sürelerininse yüksek olduğunu söyleyebilirdi.
Fakat aşağıdaki tabloda yer alan son metriğimiz ortak görüşün aksine bir tablo çiziyor diyebiliriz. Makine Öğrenmesi algoritması Oturum Sayısının dönüşümle çok küçük bir korelasyona sahip olduğunu ortaya çıkarıyor. Yani çok fazla oturum gerçekleştiren veya çok az oturum gerçekleştiren kullanıcıların hedef tamamlama sayıları birbirlerine oldukça yakın. Sitemizdeki bu hedefler bir ürün satın alma, bir e-kitap indirme, bir form doldurma gibi hedefler olabiliyorlar.
Örnek karar ağacı:
Şimdi de algoritmanın bize verdiği bu sonuçları görselleştirerek sonuçları daha iyi şekilde yorumlayalım. Daha sonra ise karar ağacımızı test veri setimize uygulayarak dönüşüm gerçekleştirecek kullanıcıları ne oranda başarılı şekilde tahmin edebileceğimize bakacağız.
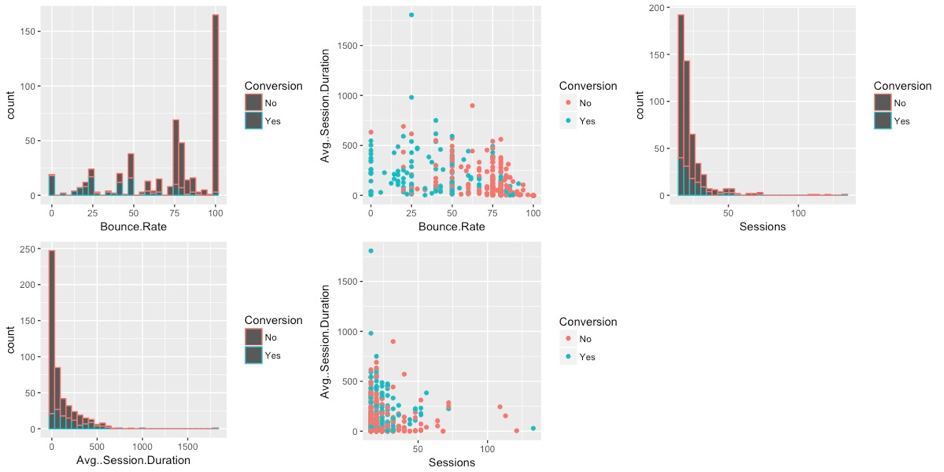
Yukarıdaki grafikler başlangıçta karışık görünebilir. Fakat ihtiyaç duyduğumuz tüm bilgileri bize bu grafikler sağlıyorlar. Soldan sağa doğru ilerlersek ilk grafiğimizde Hemen Çıkma Oranlarının azaldıkça hedef tamamlayan kullanıcı oranlarının da arttığını görüyoruz. Yeşiller hedef tamamlayan kırmızılar ise tamamlamayan kullanıcılar. İkinci grafikte Hemen Çıkma Oranı yaklaşık %50’nin altında olan kullanıcılarla üstünde olan kullanıcılar arasında hedef tamamlama anlamında net bir ayrım olduğunu görüyoruz.
Üçüncü grafikte ise Oturum sayılarının artmasının her ne kadar sayı olarak hedef tamamlamayan kullanıcıları azalttığını görsek de, aynı şey tamamlayan kullanıcılar için de geçerli. Yani oturum sayısı arttıkça dönüşüm tamamlayan kullanıcılar artış göstermiyor. Herhangi ciddi bir bağıntı yok arada.
Dördüncü grafikte Oturum sürelerinin artışının küçükte olsa dönüşen kullanıcı oranlarıyla bağlantılı olduğunu görebiliyoruz. Beşinci grafikte ise tekrardan Oturum sayılarının artışının dönüşüme yansımadığını fakat, oturum sayısı belirli bir noktaya kadar yüksek olan kullanıcılarının aynı zamanda oturum süreleri de yüksekse dönüşüm gerçekleştirdiklerini görebiliyoruz. Bu bilgilerin tümünü ML algoritmasının bize verdiği sonuçlar üzerinden de görebiliyoruz. Tabi metrik sayısı burada sadece üç olduğu için korelasyonları görebilmek de bir hayli kolay. Şimdi tahmin aşamasına geçebiliriz.
Dönüşüm Gerçekleştirecek Kullanıcıların Tahmini
Rpart’ta fitimizi gerçekleştirdikten sonra predict fonksiyonunu kullanarak test setimiz üzerinde ilgili metriklerimizi kullanarak dönüşüm gerçekleştiren kullanıcılara yönelik tahmin yapacağız. Predict fonksiyonu daha önce yaptığımız fit üzerinden verdiğimiz dataya ilişkin yüzdeler belirleyerek tahminler sağlıyor. Bu tahminleri en yukarıdaki grafiğimizdeki ilişki oranları üzerinden gerçekleştiriyor.
>
Client ID No Yes
932 0.5828989 0.41710115
4667 0.1770538 0.82294618
3906 0.9195104 0.08048961
931 0.5828989 0.41710115
2147 0.9195104 0.08048961
999 0.9195104 0.08048961
Daha sonra fonksiyonun verdiği bu tahminlere yüzde 50 üzerinden bir kota koyabiliriz. Eğer Evet değerleri %50’den yüksekse bunu dönüşüm sayacağız, eğer düşükse saymayacağız. Son olarak yaptığımız tahminleri eğer tüm kullanıcıları dönüşmeyecek olarak işaretleseydik başarı oranımız ne olurdu sonucu ile karşılaştıracağız.
- Tüm kullanıcılarımızı hedef tamamlamayacak şekilde işaretlememiz halinde elde edeceğimiz tahmin oranı: 0,746
- Oluşturduğumuz fiti bu tahmin için kullanmamız halinde ise elde ettiğimiz tahmin oranı ise: 0,842
Tabi bu oran daha fazla metriğin tahmin yapma algoritmamız içerisine eklenmesi ve daha gelişmiş Makine Öğrenmesi algoritmalarının kullanılması ile arttırılabilir bir oran.
Sonuç
Makine Öğrenmesi algoritmalarıyla site ziyaretçilerimizin hedef tamamlamaya yönelik davranışlarını çok daha net bir şekilde ortaya koyabiliyoruz. Bu algoritmaları ayrıca farklı kampanyalarda farklı ziyaretçi kitlelerinin davranışlarını ve dönüşüm oranlarını incelemek için de kullanabiliriz. Üstelik gelecekte dönüşüm gerçekleştirme potansiyeli yüksek olan kullanıcılarımızı da daha öncesinden tespit etmemiz, benzer davranışları gösteren kullanıcılara ise tekrar pazarlama stratejileri ile ulaşmak mümkün olabilir. Bu yaklaşım otomatik bir segmentasyon yaklaşımı olarak da dikkate alınabilecek bir yaklaşım.
Google Analytics içerisinde dönüşüm gerçekleştiren kullanıcılarımızı en küçük birimine kadar elle segmente etmek gibi bir durum söz konusu değil. Üstelik ziyaretçi sayısı artış gösterdikçe en basit segmentasyonlar dahi ciddi bir sorun haline gelebiliyor. ML algoritmaları ise tüm bu sorunlara yönelik çok gerçekçi bir çözüm sağlıyor diyebiliriz. Bu konuda herhangi bir sorunuz veya yorumunuz olursa lütfen paylaşmaktan çekinmeyin.
Kaynaklar:























