
Python ile SEO Crawl Analizi, Analytics ve Search Console Verilerinin İncelenmesi: Temel Kodlar
Excel ve Google Sheets hepimizin eli ayağı olmuş durumda. En temel işlerden en komplike işlere kadar illa bir yerlerde günlük rutinimize dahil oluyorlar. Özellikle SEO analistleri için ileri seviye formülleri öğrenip işlerini daha hızlı yapabilme ekstra bir beceri. Ancak veri büyüdükçe yazılan en mantıklı formül bile anlamını beklerken yitirebiliyor. Excel patlayabiliyor, Sheets yanıt vermeyebiliyor, dönüş alsak da o kadar geç dönüyor ki saatlerimiz formül yazıp beklemekle geçebiliyor. Çeşitli dualar, yalvarış ve totemler ile ekran karşısında iş yapmaya çalıştığınız illa ki olmuştur. Özetle fazla veriye sahip büyük websiteleri ile çalışmak kimi zaman kaosa dönüşebiliyor. Python işte burada devreye giriyor ve son dönemlerde özellikle SEO dünyasında da popülaritesi oldukça artmaya başlayan bir dil. Temel seviyede öğrenme ve kullanım kolaylığı, çok büyük verilerde dahi hızlıca proses edip dönüş yapması gibi artıları var.
Bu yazıda amacım en temel ve basit kodlar ile Python’ın Excel’i Pandas kütüphanesini kullanarak Excel’de yaptığımız işleri nasıl hızlıca yapabildiğimizi göstermek. Hatta aklımıza gelmeyenleri, gelse de oldukça vakit alacak işleri bir kaç satır kod ile hızlıca çözümleyip ön görü elde etmeye çalışacağım.
Gözünüz korkmasın, kodlama ve dil öğrenmek bambaşka bir dünya, bambaşka bir uğraş ancak günlük rutin işlerinizi hızlıca yapabilecek kadar kod biliyor olmanız, (ki burada hemen hemen bir çoğunu vermeye gayret edeceğim) işinizi görecek kadarını almanız dahi size oldukça vakit kazandıracaktır. Siz çok sever, modellemeler yaparak Makine Öğrenmesi ve Derin Öğrenmeye kadar devam edebilirsiniz tabi ki :) Python’ı ileri seviye öğrendiğinizde SEO’da neler yapabileceğinizi görmek istiyorsanız Hamlet Batista’nın yazıları veya JR Oakes’un yazıları ufkunuzu fazlasıyla açacaktır.
Şimdi başlayalım: Python’ı bilgisayarınıza nasıl indireceğiniz ve kullanacağınız konusu ile ilgili internette oldukça fazla bilgi var. Biz doğrudan kodlara geçelim.
Kütüphanelerin Yüklenmesi
Bu yazıda yalnızca dataframe’ler için Pandas’ı, grafikler için Mathplotlib’i kullanacağız ancak Python’da bir çok kütüphane mevcut. Burada örnek olması açısından diğer kütüphaneleri de ekliyorum, veri analizlerinde ilerlemek isterseniz bu kütüphaneler de oldukça işinize yarayacak.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
import scipy.stats as stats
warnings.filterwarnings('ignore')
Temel Kodlar ile Tarama Dosyasının Analizi
Şimdi örneğin Screaming Frog'da yaptığımız taramanın dosyasını buraya alalım:
df1 = pd.read_excel('crawl.xlsx',skiprows=1)
df1.head()
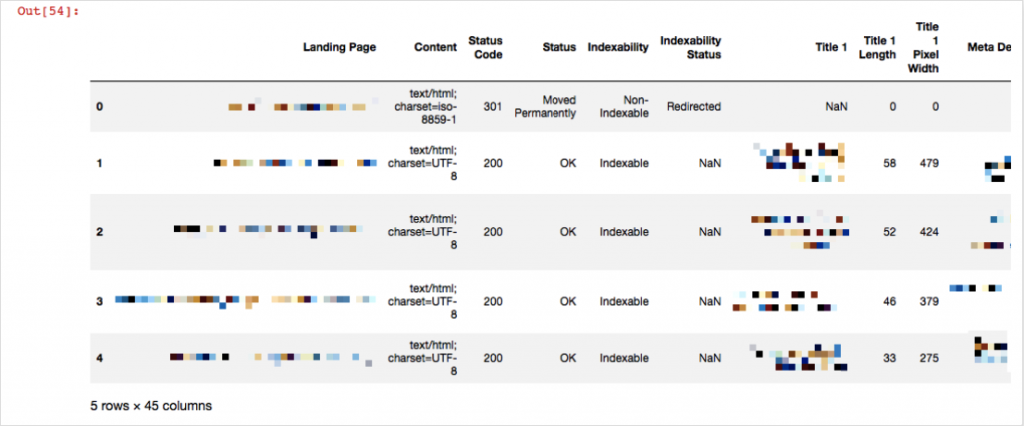
Burada pd.read_xlsx ile tarama dosyamızı okuduk ve bu dosyanın bilgilerini df1'de sakladık. 'csv' dosyası için de pd.read_csv uzantısını kullanabiliriz. head() komutu ile de ilk beş satırımızı görüntülüyoruz. skiprows=1 yapmamızın sebebi ise Screaming Frog çıktısında ilk satırda değil ikinci satırda kolon isimlerinin yer alması. Diyelim ki 404 yanıt kodu veren sayfalarınızı görmek ve bunları farklı bir dosyaya kaydetmek istiyorsunuz:
df404 = df1[df1['Status Code'] == 404] df404
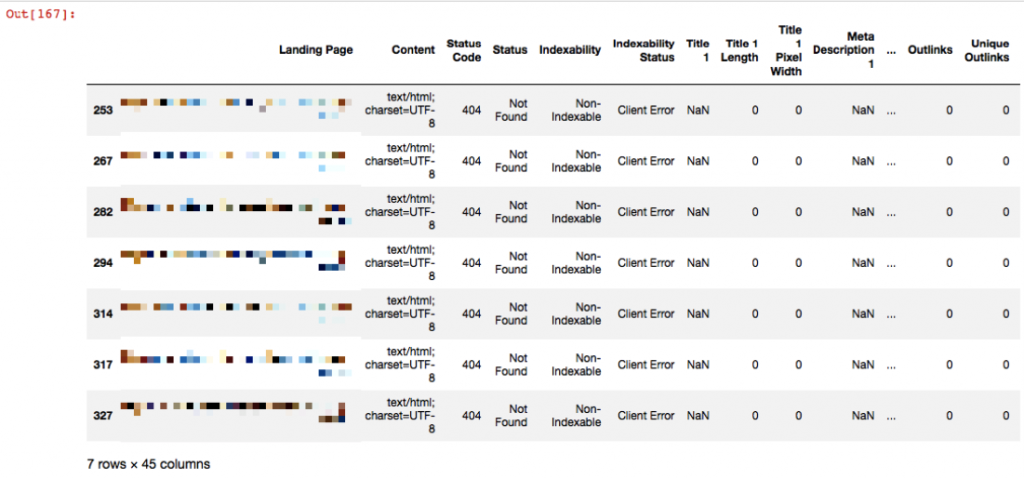
Python'da eşitliği göstermek için == işaretini ,eşit değili göstermek için != işaretlerini kullanıyoruz. Şimdi ayrı bir dosyaya kaydedelim:
df404.to_csv('export404.csv', sep='\t', encoding='utf-8')
404 yanıt kodu veren sayfaları export404.csv isimli dosyaya aktardık. Dolayısıyla farklı satırlarda yazacağınız kodlar ile duplicate sayfaları, redirect sayfaları, title etiketi bulunmayan sayfaları ve daha bir çok crawl çıktısını farklı yerlerde tutabilir ve bir sonraki crawl analizinde yalnızca bu kodları çalıştırarak manuel inceleme öncesi crawl çıktılarınızı saniyeler içinde hazır etmiş olabilirsiniz. Örneğin title etiketi bulunmayan sayfaları tespit edelim:
dtitle = df1.loc[df1['Title 1'].isnull()]
Burada isnull() komutu Title 1 sütununda NaN yani olmayan değerleri tespit ediyor. .loc ise o satırların tespiti ve ekrana basılması için gerekli. Title 1 yerine 'Meta Description 1' yazarsanız bu sefer de meta description etiketi bulunmayan sayfaları size dökecektir. Yine yukarıda 404 örneğinde gösterdiğimiz gibi bu verileri farklı dosyalara kaydederek incelemenize devam edebilirsiniz. Örneğin bilgi bulunmayan NaN satırlarının yoğunluğunu bilmek istiyorsunuz. Bunu excel'de tek tek filtreleyerek yaptığınızı düşünün. Bunun yerine Python'da tek satırlık kod ile veriniz hakkında fikir sahibi olabilirsiniz:
plt.figure(figsize=(10,8)) sns.heatmap(df1.isnull(),yticklabels=False,cbar=False,cmap="viridis") plt.show()
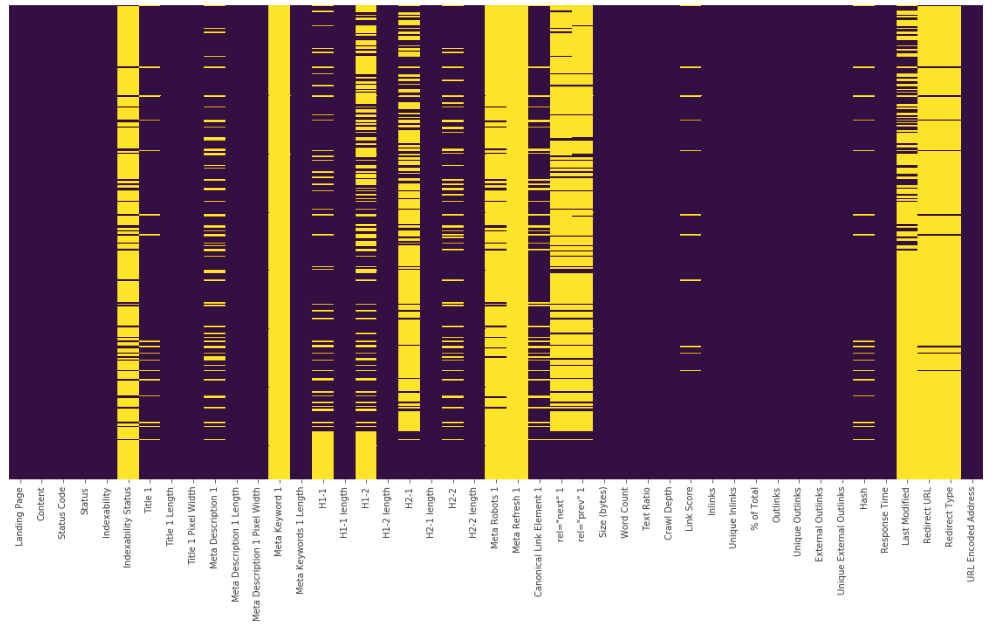 Bu heatmap'te sarı çizgiler NaN değerlerini ifade ediyor. Bunu heatmap olarak değil de adet olarak görmek isterseniz de:
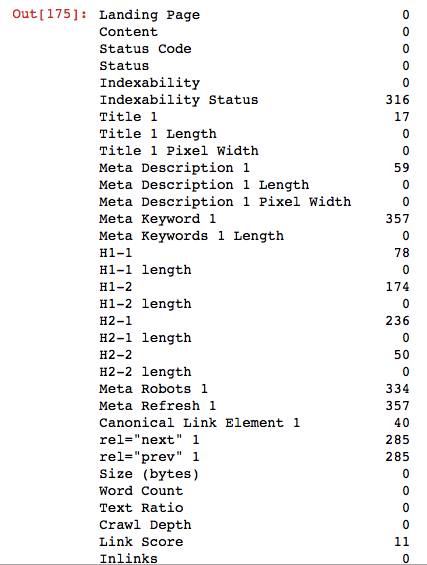
Bu heatmap'te sarı çizgiler NaN değerlerini ifade ediyor. Bunu heatmap olarak değil de adet olarak görmek isterseniz de:
df1.isnull().sum()
Crawl Analizini Google Analytics Verileri İle Birleştirme
Basit tarama analizimizi tamamladığımıza göre bu verileri Analytics verileri ile eşleştirerek biraz daha derin incelemeler yapabiliriz. Öncelikle son 1 aylık veya incelemek istediğiniz veriye göre son 3 aylık Landing Page raporunu alın. İki dosyayı URL'lere göre birleştireceğiz. Ancak öncelikle dosyamızı crawl dosyasında yaptığımız gibi okuyalım:
df_analytics = pd.read_excel('analytics.xlsx')
df_analytics.head()
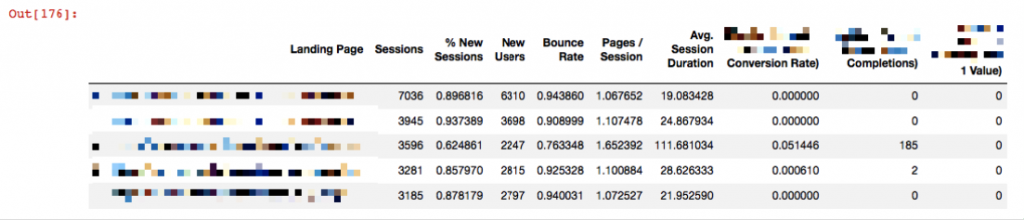
Şimdi crawl dosyamız ile analytics dosyamızı birleştireceğiz, bunun için pd.merge() komutunu kullanıyoruz:
merged = pd.merge(df1, df_analytics, left_on='Landing Page', right_on='Landing Page', how='outer') merged.head()
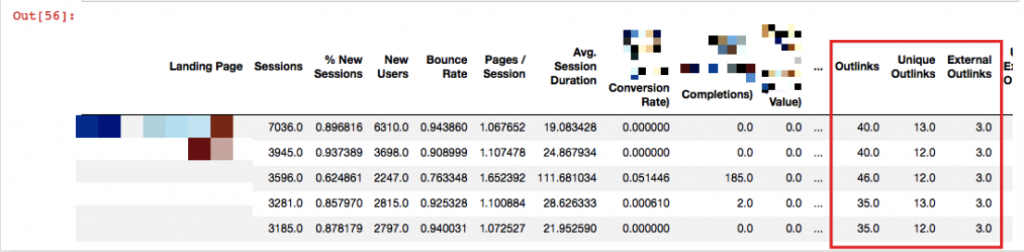
Landing Page'lere karşılık olarak crawl sonuçları da dosyanın sağına eklenmiş durumda. Son merged isimli dosyanın hangi verileri tuttuğuna bakmak ve bu verilerin tiplerini görmek için info() komutunu kullanabiliriz:
merged.info()
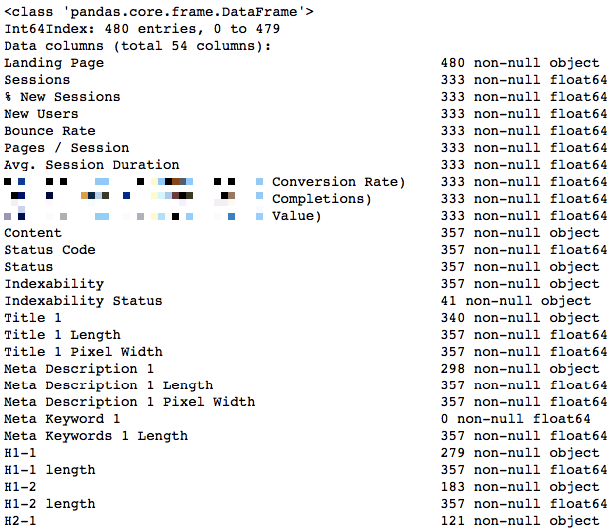
Toplam 54 kolonumuz mevcut. Kolon isimlerinin karşısında veri tipleri de bulunuyor. Object string/text türünde bir veri olduğunu, float64 virgülden sonra ondalık basamakları olan bir sayı olduğunu, burada yok ancak integer ise tam sayı olduğunu ifade ediyor.
Crawl Depth İncelemesi
Örneğin tarama sonucunda crawl depth dağılımına bakalım:
plt.figure(figsize=(10,5))
merged['Crawl Depth'].value_counts().sort_values().plot(kind = 'barh')
plt.xlabel("URL Counts")
plt.ylabel("Crawl Depth")
plt.title("Crawl Depth / Pages")
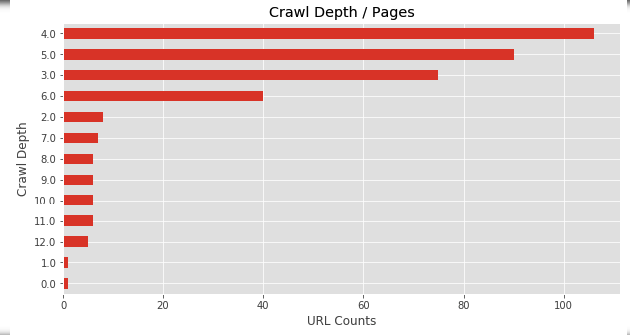
Bu grafiği zaten crawler araçları ile de görebiliyoruz. Sayfalarımız 4., 5., 6. derinliklerde yoğunlaşmış görünüyor. Şimdi ise farklı bir yaklaşımda bulunalım ve Crawl Depth'e karşı Session grafiği çizelim.
plt.figure(figsize=(10,5))
plt.style.use('ggplot')
plt.bar(merged['Crawl Depth'], merged['Sessions'], color='purple')
plt.xlabel("Crawl Depth")
plt.ylabel("Sessions")
plt.title("Crawl Depth & Sessions")
plt.show()
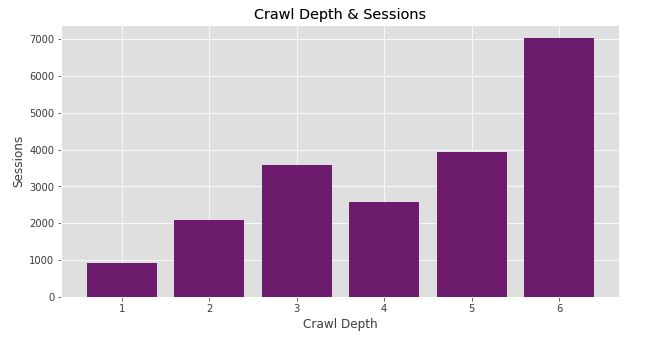
Enteresan bir trend ile karşılaştık. En çok oturum aldığımız sayfalar Crawl Depth 6'da toplanmış görünüyor. Kıymetli sayfalarımızın Googlebot tarafından 6 adımda ulaşılabilir olması istediğimiz bir yaklaşım değil. Önemli sayfalarımız kolay ulaşılabilir olmalı ve sıklıkla crawl edilebilmeli. Belki 6. derinlikte yer alan sayfalar çok daha iyi performans gösterebilecekken şu an onları oldukça uzakta tutuyoruz.
Bu sayfaları daha öne çekmeli miyiz? Bunlar bir grup sayfa mı yoksa tek bir sayfanın yüksek session sayısı verimizi yanıltıyor olabilir mi? Crawl Depth 5'te de aynı şekilde yer alan sayfalarımız hangisi?
Sorular soruları doğuruyor, doğru yoldayız :) Bu soruları cevaplayabilmek için çıktılarımızı incelemeli, sebepleri anlamalı ve gerekliyse aksiyon alarak önemli sayfalarımızı daha öne çekebilmeliyiz. Şimdi Crawl Depth 6 da bulunan sayfalarımızı çekelim:
df_CD6 = merged[merged['Crawl Depth'] == 6] df_CD6.head()
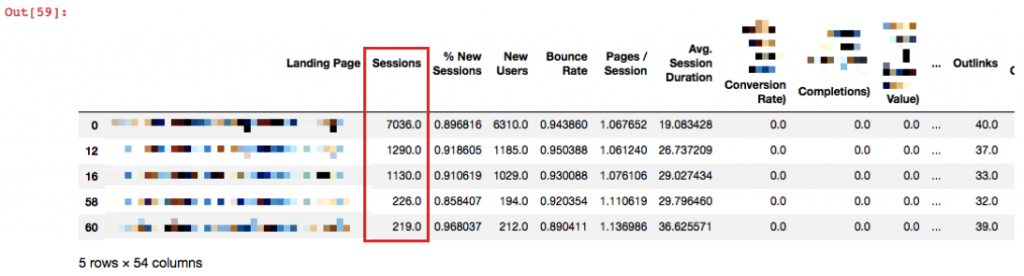
Özellikle ilk 3 sayfayı incelemeli, eğer gerekliyse bu sayfaların crawl depth'ini düşürmeliyiz.
Internal Linking İncelemesi
Crawl Depth gibi incelemek için seçtiğimiz bir diğer metrik Unique Inlinks olsun. Bu sefer scatter grafiği çizip inlink dağılımını inceleyelim:
plt.figure(figsize=(15,10)) plt.scatter(merged['Unique Inlinks'], merged['Sessions']) plt.show()
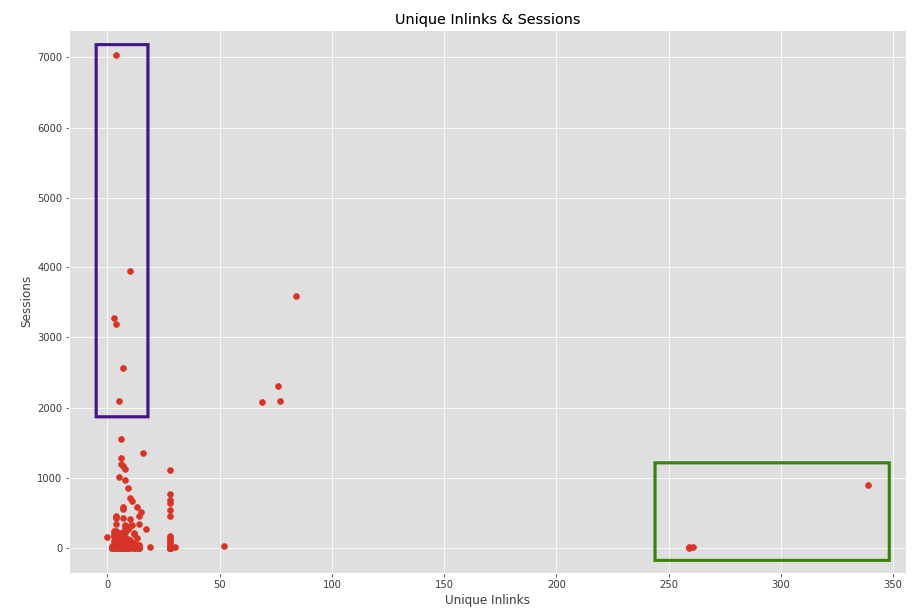
İç linkleme önemli bir etken sayfaların performansı için. Sayfaların birbirine değer aktarımını da baz alırsak gereksiz yere link vermek veya iyi performans gösterebilecek bir sayfaya yeterli iç linkleme yapmamak optimizasyon gerektiren bir konu. Örneğin yukarıdaki grafiği inceleyelim. Sağ kısımda bulunan yeşil ile işaretlediğim sayfalar oldukça fazla iç linke sahipken çok iyi performans göremediğimiz sayfalar.
Bu sayfalar gerçekten kötü performans gösteren sayfalarımız mı, bu kadar iç linkleme yapmamıza gerek var mı yoksa bu sayfalar yalnızca menüden linklenen sayfalarımız olduğu için mi bu kadar çok linke sahip?
Yukarıdaki durumda menüden linklenen sayfalar olduğunu tespit ettik. Bu durumda da bu sayfaların menüden linklenmesine gerek olup olmadığını araştırabilirsiniz, tamamen stratejiye bağlı bir durum. Diğer yandan mor ile işaretlediğimiz sayfalara baktığımızda site genelinde iyi performans gösteren sayfalar olduğunu görüyoruz. Ancak site içi linklemeleri dağılımsal olarak çok da yeterli gibi durmuyor. Bu sayfaları çekebilir, alakalı olan diğer sayfaları tespit ederek bu sayfaların iç linklemesini artırabilirsiniz.
Tabi ki bu sayfaların optimizasyona ihtiyacı varsa. Bu durumda Search Console verilerini de veri setimize ekleyerek bunu tespit edebiliriz.
Response Time İncelemesi
Crawl genelinde sayfalarımızın ne kadar hızlı veya ne kadar yavaş yanıt verdiğini gözlemlemek için bir dağılım grafiği çizebiliriz:
plt.hist(merged['Response Time'], color = 'green')
plt.xlabel("Response Time (seconds)")
plt.ylabel("URL Counts")
plt.title("Response Time & URL counts")
plt.show()
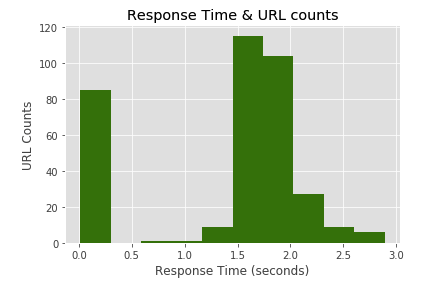
Belirli bir grup sayfamız oldukça hızlı yanıt dönmüş görünüyor. Ancak kalan sayfalarımızın bir çoğu 1.5 ve 2 saniye arasında cevap vermiş. Sayfalarımızın geç açıldığını görüyoruz. Bunun için örneğin 2 saniye üstünde yanıt veren sayfalarımızı çekebilir ve bunların hız skorlarını pagespeed insights aracı ile inceleyebiliriz.
df4 = merged[merged['Response Time'] >= 2.0] df4.head()
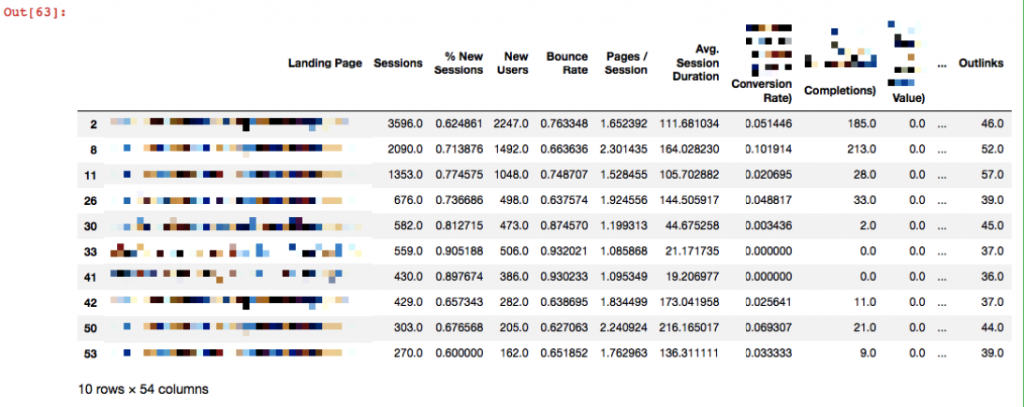
Orphan Sayfaların Tespiti
Analytics verisi ile crawl verisini birleştirdiğimiz için potansiyel orphan page'leri tespit edebiliriz. Eğer analytics'de session sayılan bir sayfa crawl analizinde gelmemişse bu sayfa ya yönlendirilmiştir ve site içinden kaldırılmıştır veya sayfa canlıda olmasına rağmen site içinde herhangi bir yerden linklenmiyordur.
d_orphan = merged.loc[merged['Status Code'].isnull()] d_orphan
Crawl edilen her bir URL'in bir statü kodu olacağı için NaN olarak tespit edilmemiş olanlar Analytics verisinden gelen sayfalardır diye düşünerek statü kodu boş olan satırları çağırdığımızda potansiyel orphan page olabilecek sayfaları çekmiş oluyoruz:
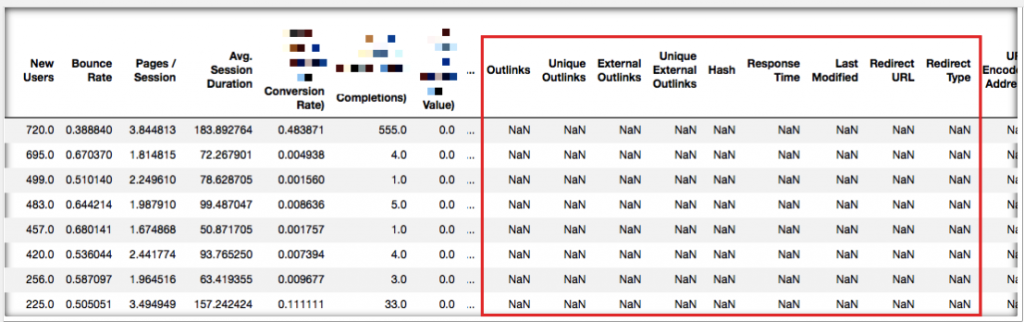
Yukarıdaki grafikten de görebileceğiniz üzere crawl'da bulunmayan sayfaları tespit etmiş olduk. Şimdi o sayfaları tekrar tarayarak içlerinde 200 yanıt kodu olan var mı diye inceleyebiliriz.
Yeni Bir Kolon Ekleme ve Sayfaları Gruplandırarak Etiketleme
Diyelim ki sayfalarınızın belirli bir URL pattern'i mevcut ve siz bu sayfaları değerlendirirken gruplandırarak değerlendirmek istiyorsunuz. Bizim örneğimizde bu blog sayfaları olacak. URL'lerde /blog/ geçtiği için, ben bunları tespit etmek ve yeni bir kolona bu sayfaların karşısına blog etiketi koymak istiyorum:
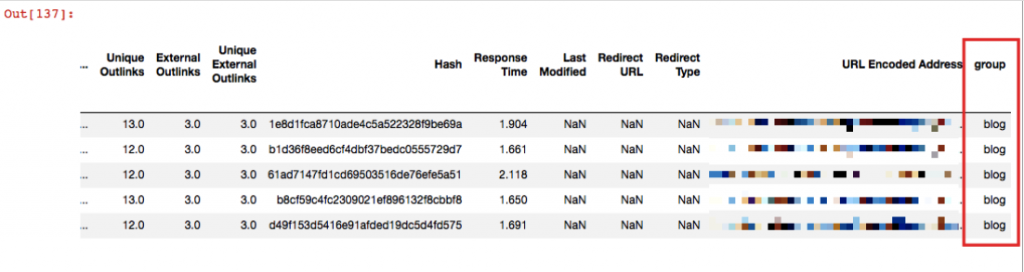
d_blog = merged[merged['Landing Page'].str.contains('^https://www.example.com/blog/')]
d_blog['group'].fillna("blog", inplace = True)
d_blog.head()
['group'] diye bir kolonum olmamasına rağmen yukarıda bu kolonu tanımladık ve str.contains komutu ile sayfaları tespit ettik. fillna() komutu ise boşlukları bununla doldur demek. Biz etiket olarak blog seçtik.
Search Console Verisini Ekleme
Şimdi de yine bir veri dosyasını var olan veri setimize ekleyerek datamızı büyütelim:
d_console = pd.read_excel('console.xlsx')
merged2 = pd.merge(merged, d_console, left_on='Landing Page', right_on='Landing Page', how='outer')
merged2.head()

Yukarıda görebileceğiniz üzere Console verileri de landing page'lerin karşısında yerini aldı. Yine Crawl Depth'i inceleyerek sayfaların ortalama pozisyonlarına bakabiliriz:
plt.figure(figsize=(10,5))
plt.style.use('ggplot')
plt.bar(merged2['Crawl Depth'], merged2['Position'], color='purple')
plt.xlabel("Crawl Depth")
plt.ylabel("Position")
plt.title("Crawl Depth & Position")
plt.show()
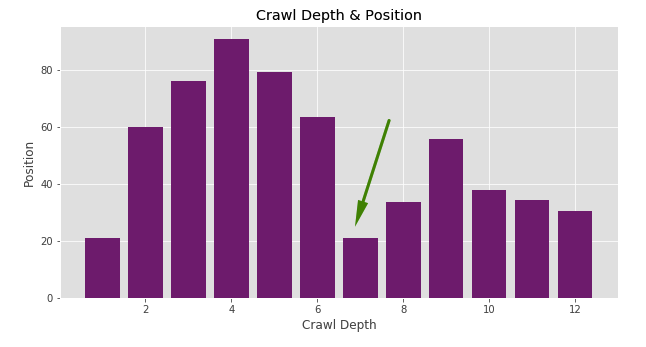
Örneğin sayfanın görünürlük aldığı tüm kelimelerdeki ortalama pozisyonu 20 civarında olan ancak Crawl Depth 7'de bulunan sayfalar olduğunu görüyoruz. Bir ihtimal optimizasyon yaptığımızda hızlıca etkisini görebileceğimiz sayfalar olabilir. Dolayısıyla Crawl Depth 7'de bulunan sayfaları çekerek inceleyebilir, optimizasyon için onları önceliklendirebiliriz. Ancak ortalama pozisyon verisi her zaman bizi doğru yönlendirmeyebilir. Burada kelimeleri de inceleyerek analiz etmek çok daha doğru olacaktır.
Text Bulutu Grafiği
Majestic isimli araçtan aşina olduğumuz, kullanım sıklığına göre kelime bulutu grafiği hem görsel olarak şık duran hem de kelime yoğunluğunu hızlıca tespit etmemize yarayan bir grafik. Anchor text'lerde veya belirli bir grup sayfanın title'ını incelemek için kullanabilirsiniz. Kod örneğini ve örnek görseli farklı bir veri setinden oluşturarak aşağıda paylaşıyorum:
# öncelikle wordcloud kütüphanesini import ediyoruz
from wordcloud import WordCloud
harvard = df[df['Institution'] == 'HarvardX']
wordcloud = WordCloud(background_color="white").generate(" ".join(harvard["Course Subject"]))
plt.figure(figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Bitirirken...
Gördüğünüz gibi birbirinden çok da farklı olmayan kodlarla bir çok analiz yapabildik. Sadece bu basit temel kodları öğrenerek özellikle büyük verilerinizde hızlıca analizler yapabilirsiniz. Aslında verinizin büyük olmasına gerek de yok. Hızlıca grafikler oluşturarak ön görü topladığımızı fark etmişsinizdir. Bunları Excel veya Google Sheets üzerinde yapmak istediğinizde süre bakımından oldukça farklı bir emek ortaya koymanız gerekecektir. Dolayısıyla yalnızca yukarıda paylaştığım temel kodları dahi bilseniz, günlük rutin işlerinizde oldukça faydasını göreceğiniz kesin.
Eğer yapmak istediğiniz bir işi yukarıdaki kodlar içerisinde bulamazsanız da aramaya inanın :) Stackoverflow gibi sitelerde muhakkak cevabını bulacaksınızdır.

























