


Common Mistakes in Robots.txt Files
The robots.txt file is an important control mechanism that tells search engines which pages they should crawl. However, when misconfigured, it can negatively affect SEO performance. Especially on e-commerce and content-focused sites, small mistakes can seriously harm organic visibility and lead to critical crawlability issues. In this article, I will talk about the most frequently encountered mistakes in robots.txt files.
First, let's provide a brief explanation of what robots.txt is.
What is Robots.txt?
The robots.txt file is a simple text file located in the root directory of a website that informs search engine bots which pages should be crawled and which should not. Through this file, site owners can hide specific directories or pages from search engines, thereby using their crawl budget more efficiently and preventing unnecessary content from being indexed.
For details, you can review the detailed content about robots.txt written by our team member, Samet Özsüleyman.
Common Mistakes in Robots.txt Files
1 - 404 or Inaccessible Robots.txt Files
One of the most common mistakes is the robots.txt file not existing at all or being inaccessible on the server. Before search engine bots start crawling a site, they first check the robots.txt file. If the robots.txt file returns a 4xx code, Googlebot acts as if the robots.txt file does not exist. In other words, it assumes that no crawling restrictions have been made.
If Googlebot encounters a 5xx, i.e., a server error, with the robots.txt file, the following steps are applied:
- It does not crawl the site for 12 hours, but continues to try to fetch the robots.txt.
- If it cannot fetch a new version, it uses the last working version.
- If there is no cached version, it assumes there are no crawl restrictions.
- If the server error is not fixed in 30 days, Googlebot acts as if the robots.txt file does not exist. You can find detailed information in Google's resources.
To manage the crawl budget efficiently, it is recommended that you create a working robots.txt file with a 200 status code.
2 - Use of Slash (/)
Another common mistake made in the robots.txt file is the incorrect or incomplete use of the "/" character. Search engine bots pay attention to this character when interpreting directories and files. Its incorrect use can cause unexpected pages to be blocked or unintentionally left open for crawling.
For example, the following command means that all pages are closed to crawling.
User-agent: *
Disallow: /
The following command means that no pages are closed to crawling. Therefore, the two files are completely different.
User-agent: *
Disallow:
To give an example using URL directories, the following command closes the /blog page to crawling. However, subpages like /blog/what-is-robots-file continue to be crawled.
User-agent: *
Disallow: /blog
When we add a slash to the end, the /blog/ directory will be completely closed to crawling.
User-agent: *
Disallow: /blog/
Therefore, you need to be careful about which pages you close to crawling when creating a robots.txt file. For checking, you can use Technical Seo’s robots.txt testing tool.
Tired of reading?
You can also listen to this blog post as a podcast we created with Google NotebookLM on Spotify.
3 - Allow vs. Disallow Commands
The combined use of Allow and Disallow commands in a robots.txt file can often lead to confusion. These two commands are used together, especially when you want to allow some pages within a directory while closing that directory to crawling. However, in this case, it is very important that the rules do not conflict with each other and to understand how search engines will interpret them.
For example, the following robots.txt file closes the /products/ directory to crawling while leaving the /products/women directory open to crawling.
User-agent: *
Disallow: /products/
Allow: /products/women/
Advanced search engine bots like Google recognize the allow command, but less advanced search engines may interpret it differently. Therefore, it is recommended not to use complex rule structures unless necessary.
4 - Misinterpreting the File Reading Order
One of the common mistakes made in the robots.txt file is the misconception that the rules are read in order from top to bottom. Modern crawlers like Googlebot evaluate rules according to their degree of specificity; that is, more specific rules have priority over general ones. When crawlers match URLs with robots.txt rules, they look at the length of the rule's path and use the most detailed one. In the case of conflicting rules, the least restrictive rule becomes valid, including those with wildcards.
For example, because the following robots.txt commands conflict, Google will use the Allow command.
Allow: /page
Disallow: /page
For example, on a website, we want to close URLs under /blog to crawling, but we want the content /blog/post1.html to be crawlable. In this case, the allow and disallow commands can be used as follows.
Disallow: /blog
Allow: /blog/post1.html
For detailed information about the priority order of rules, you can take a look at the content on how Google interprets the robots.txt specification.
5 - Robots.txt File Not Located in the Root Directory
The robots.txt file must be located in the root directory of your site. A robots.txt file located in subdirectories or under a different path is considered invalid by search engines. This means that no restrictions are applied.
For example, the robots.txt file created for the domain https://www.example.com should look like the following.
https://www.example.com/robots.txt
Robots.txt files not located in the root directory, like the following, are not valid.
https://www.example.com/config/robots.txt
https://www.example.com/path/robots.txt
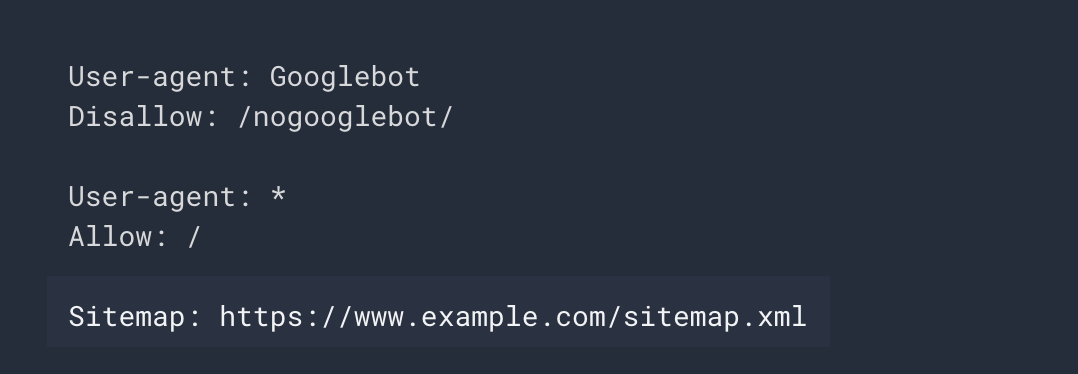
6 - Not Adding a Sitemap to the Robots.txt File
Google resources have described the sitemap line as optional. Therefore, not adding the sitemap to the robots.txt file is not exactly a mistake, but if you want the sitemap to be crawled faster and possibly more frequently, I recommend adding the sitemap to the robots.txt file.

When adding a sitemap to the robots.txt file, you need to make sure that the sitemap contains the full URL. Otherwise, your sitemap will not be crawled. A robots.txt file with a sitemap added looks like the following.
7 - Marking URLs Covered by Robots.txt as Noindex
One of the frequently encountered mistakes is marking a URL that is closed to crawling by the robots.txt file as noindex at the same time. If a page is closed to crawling with robots.txt, search engine bots cannot see the content of this page and therefore cannot determine whether it has a noindex tag. The search engine will continue to keep this page in its cache instead of removing it from the index. For this reason, you need to be careful when taking actions such as status codes and indexability for the pages you close to crawling via robots.txt.
For example, to completely remove the /tag/ path you blocked via robots.txt from the index, you should first remove the /tag/ line in robots.txt, and then mark the /tag/ pages as noindex. After the pages are removed from the index, you can re-add the /tag/ path to the robots.txt file to prevent the pages from being crawled.
8 - Development Environments and Test Site Being Open to Crawling
The indexing of staging or test environments can cause duplicate content issues. Therefore, it is recommended to close development environments and test sites to crawling with robots.txt. You can close your test site to crawling with the following commands.
User-agent: *
Disallow: /
This command only contains directives for bots. To protect such pages comprehensively, methods such as HTTP basic auth or IP blocking can be preferred.
The robots.txt file, despite its simple structure, has a great impact in terms of SEO. Configuration errors that seem small can seriously affect the site's crawlability and therefore its organic visibility. For this reason, you should be careful when creating a robots.txt file for your website, check it regularly, and get support from technical SEO tools or experts if necessary.























