


Xpath SEO: Screaming Frog'da XPath ile Veri Kazıma & Kullanabileceğiniz Temel Komutlar
SEO dünyasından genellikle Screaming Frog gibi crawl araçları sayesinde adını duyduğumuz XPath, veri kazıma (web scraping) konusunda oldukça kullanışlı bir çeşit sorgu dilidir. Python, Javascript gibi programlama dillerine nazaran kolaylıkla veri çekebilmenizi sağlayan XPath ile sayfada ihtiyacınız olan birçok bilgiyi saniyeler içerisinde elde edebilirsiniz. Blog yazımda genel XPath tanımı ve analiz yaparken kullanabileceğiniz belli başlı XPath komutlarına ve yazdığınız XPath’leri Screaming Frog gibi crawlerlar aracılığıyla nasıl kullanabileceğinize değineceğim.
Ben, temel XPath komutlarını test edebilmek için Chrome XPath Helper eklentisi kullanıyorum. Siz de bu eklenti ile yazdığınız XPath’lerin çalışıp çalışmadığını kolayca test edebilirsiniz. Site genelinde inceleme yapmak istiyorsanız da içerik sonunda yer alan Screaming Frog’da XPath Ayarları Nasıl Yapılır? başlığı altında Screaming Frog için XPath ayarlarını yapabilirsiniz.
- XPath Nedir?
- XPath Türleri Nelerdir?
- XPath’in Temel Kavramları Nelerdir?
- Temel XPath Komutları
- Screaming Frog’da XPath Ayarları Nasıl Yapılır?
XPath Nedir?
XPath bir XML dokümanı içerisinde aradığımız elemanlara ve bilgilere kolayca ulaşmamızı sağlayan bir çeşit XML kılavuzudur. XPath için XML gibi karmaşık bir dilin içerisinde dolaşabilmemiz adına oluşturulmuş bir kısayoldur da diyebiliriz. XPath yalnızca XML içerisinde değil, HTML içerisinde de aradığımız tüm verileri bizlere sunabilir.
Temel XML kavramları arasında yer alan XPath, Javascript, Java, Python gibi birçok programlama dili içerisinde de kullanılabilir.
XPath Türleri Nelerdir?
Absolute XPath:
Öğeyi bulmanın doğrudan yoludur, ancak Absolute XPath’ın dezavantajı, öğenin yolunda herhangi bir değişiklik yapılması durumunda XPath’ın başarısız olmasıdır. Devtools üzerinden copy full XPath ile sayfada yer alan dilediğiniz ögenin yolunu bulabilirsiniz.
Örnek:
/html/body/div[3] bir absolute XPath örneğidir.
Relative XPath:
Öğeyi DOM içerisinde her yerde arayabileceğiniz XPath yöntemidir. // ile başlar. Web site mimarisinde oluşabilecek değişiklikler için herhangi bir ögeyi test ederken genellikle relative XPath kullanılır. Devtools üzerinden copy XPath ile sayfada yer alan dilediğiniz ögenin relative XPath’ine ulaşabilirsiniz.
Örnek:
//*[@id="123"]/div bir relative XPath örneğidir.
XPath’in Temel Kavramları Nelerdir?
Düğüm (node):
XML DOM (Document Object Model) bir XML belgesini okuyabilmenize ve değiştirmenize olanak sağlayan bir bellek içi gösterimidir ve XML belgesi içerisinde yer alan her parça düğüm (node) olarak nitelendirilir.
Aşağıda örnek XML dosyası verilmiştir.
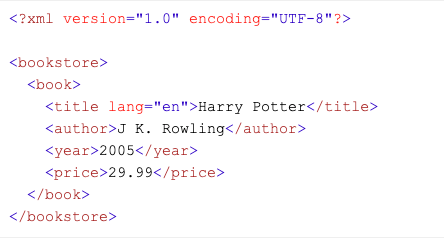
Bu dosyada yer alan bookstore, book, title, author, year, price elementlerinin her biri düğüm olarak adlandırılır. Burada dikkat edilmesi gereken şey DOM içerisindeki hiyerarşidir. <bookstore> kök düğüm olarak adlandırılırken <book> alt düğüm, alt düğüm içerisinde yer alan metinler ise metin düğüm olarak adlandırılır.
Attribute:
XML dokümanı içerisinde yer alan düğümlerin class, id, href, lang gibi özelliklerine attribute adı verilir. Yukarıdaki örnekte yer alan lang etiketi bir attribute elementidir.
Parent:
XML dokümanı içerisinde yer alan en üst seviye elemente parent element adı verilir. Yukarıdaki örnekte yer alan <bookstore> bir parent elementtir.
Child:
XML dokümanındaki parent elementler içerisinde yer alan aynı seviyeye sahip diğer elementlerdir. Yukarıdaki örnekte yer alan <title> elementi <book> elementinin child elementidir.
Sibling:
Aynı parent altında yer alan, aynı derinlik seviyesine sahip elementler sibling, yani kardeş element olarak adlandırılır. Örnekte yer alan <title>, <author>, <year> ve <price> elementleri sibling’dir.
XPath temel söz dizimi en basit haliyle aşağıdaki gibidir:
XPath = /parent_tag/child_tag[@attribute=’value’][index]
Temel XPath Komutları
Başlık Etiketleri
Crawlerlar genelde yalnızca h1 ve h2 başlık etiketleri hakkında bilgi verirler. //hx ile sayfada yer alan diğer başlık etiketlerini bulabilirsiniz.
Örneğin, h3 başlık etiketlerini bulmak içi n→ //h3
Sayfada kullanılan h3 etiketlerinin sayısını bulmak için → count(h3)
Sayfada yer alan ilk 10 h3 etiketini bulmak için → /descendant::h3[position() >= 0 and position() <= 10]
Sayfada yer alan h3’lerin uzunluğunu hesaplamak için → string-length(//h3)
Hreflang Etiketleri
Sayfada yer alan hreflang etiketlerini bulmak için → //*[@hreflang]/@hreflang
Yapılandırılmış Veriler
Sayfada yer alan yapısal verileri bulmak için → //*[@itemtype]/@itemtype
Sosyal Medya Etiketleri
Sayfada yer alan Open Graph, Twitter card gibi sosyal medya etiketlerini bulabilmek için aşağıdaki XPath’leri kullanabilirsiniz.
//meta[starts-with(@property, 'og:title')]/@content
//meta[starts-with(@property, 'og:description')]/@content
//meta[starts-with(@property, 'og:type')]/@content
//meta[starts-with(@property, 'og:site_name')]/@content
//meta[starts-with(@property, 'og:image')]/@content
//meta[starts-with(@property, 'og:url')]/@content
//meta[starts-with(@property, 'fb:page_id')]/@content
//meta[starts-with(@property, 'fb:admins')]/@content
//meta[starts-with(@property, 'twitter:title')]/@content
//meta[starts-with(@property, 'twitter:description')]/@content
//meta[starts-with(@property, 'twitter:account_id')]/@content
//meta[starts-with(@property, 'twitter:card')]/@content
//meta[starts-with(@property, 'twitter:image:src')]/@content
//meta[starts-with(@property, 'twitter:creator')]/@content
E-Mail Adresleri
Sayfada yer alan e-mail adreslerini bulmak için → //a[starts-with(@href, 'mailto')]
iFrame
Sayfada yer alan iframe etiketlerini bulmak için → //iframe/@src
Sayfada yer alan youtube videolarını bulmak için → //iframe[contains(@src ,'www.youtube.com/embed/')]
Örneğin, Google Tag Manager dışındaki iframe etiketlerini bulmak için → //iframe[not(contains(@src, 'https://www.googletagmanager.com/'))]/@src
AMP Sayfalar
AMP ile sunulan sayfaları bulmak için → //head/link[@rel='amphtml']/@href
Meta Viewport Etiketi
Meta viewport etiketlerini bulmak için → //meta[@name='viewport']/@content
Count Kullanımı
Yazdığınız XPath’in başına “count” ekleyerek aradığınız sonuç sayısına ulaşabilirsiniz.
count(//h3) → Sayfadaki h3 sayısını verir.
Attribute Komutları
//*[@id="örnek"] → Sayfa içerisinde id’si “örnek” olan tüm elementleri bulur.
count(//*[@id="örnek"]) → Sayfa içerisinde id’si “örnek” olan element sayısını verir.
//*[@class="örnek"] → Sayfa içerisinde class’ı “örnek” olan tüm elementleri bulur.
count(//*[@class="örnek"]) → Sayfa içerisinde class’ı “örnek” olan element sayısını verir.
AND Kullanımı
XPath’te tek satırda iki kıstas belirlemek istiyorsanız “|” sembolü kullanabilirsiniz.
Örneğin,
//book/title | //book/price → Book elementi altında yer alan tüm price ve title elementlerini getirir.
İşinize Yarayabilecek Diğer Komutlar
Sayfa içerisinde “SEO” kelimesini içeren anchor textler üzerinden hangi URL’lere link verildiğini bulmak için → //a[contains(.,'SEO')]/@href
Sayfada içerisinde “SEO” geçen anchor textleri bulmak için → //a[contains(.,'SEO')]
NOT: XPath’te büyük küçük harf duyarlılığı mevcuttur. Dolayısıyla sayfada “SEO” için arama yaptığınızda “seo” kelimesi içeren anchor textleri bulamazsınız.
Sayfada yer alan ve içinde “seo” geçen URL’lere linklenen anchor textleri bulmak için → //a[contains(@href, 'seo')]
İçinde “seo” geçen linkleri bulmak için → //a[contains(@href, 'seo')]@href
Yukarıdaki XPath büyük/küçük harf duyarlıdır. Sayfada yer alan içinde “seo” geçen büyük/küçük harf duyarlılığı bulunmadan tüm linkleri bulmak için → //a[contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'seo')]/@href
Sayfada yer alan nofollow linkler bulmak için → //a[@rel="nofollow"]
Screaming Frog’da XPath Ayarları Nasıl Yapılır?
Screaming Frog custom extraction alanını kullanarak da yazdığınız XPath’leri site genelinde kolaylıkla inceleyebilirsiniz. Bunun için aşağıdaki adımları uygulayabilirsiniz.
- Configuration alanından Custom → Extraction’ı seçin.
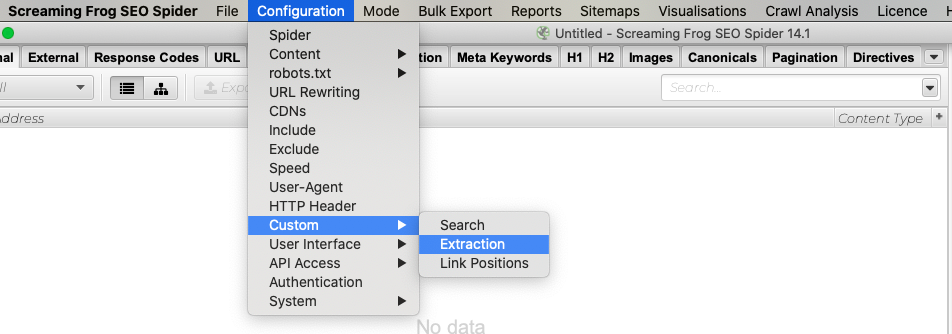
- Ardından Extraction 1 kısmına yazdığınız XPath’i açıklayacak bir ifade girin. (Örneğin, sayfada http sayfalara link verilip verilmediğini gösteren bir XPath yazıyorsanız bu alanı “HTTP Linkler” şeklinde düzenleyebilirsiniz.
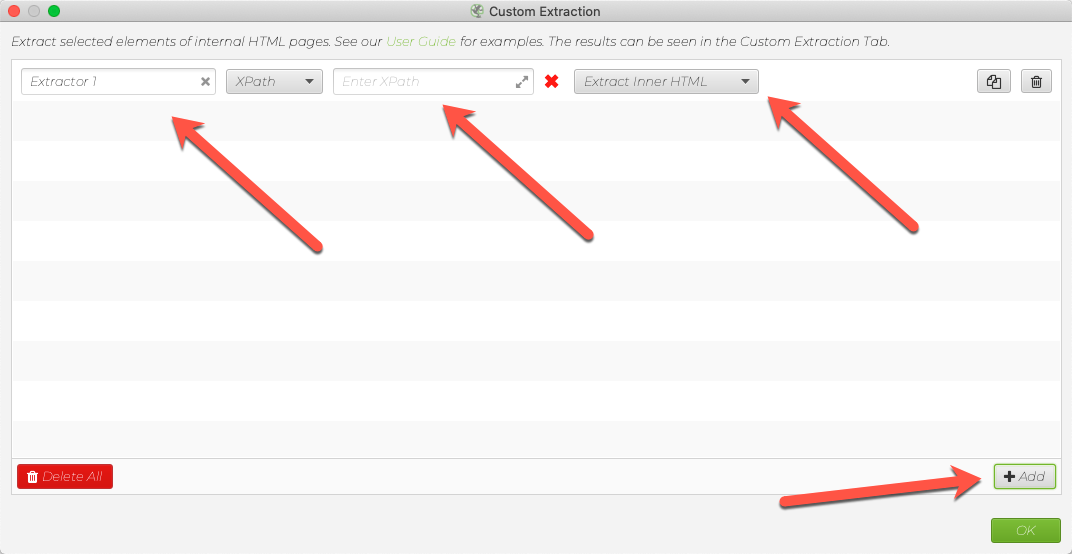
Enter XPath alanına yazdığınız XPath’i girin. Birden fazla XPath test edebilmek için sağ altta yer alan Add butonuna tıklayın ve diğer XPath’leri de girin.
Default olarak Extract Inner HTML yazılı kısımdan ise gireceğiniz XPath count gibi bir fonksiyon içerecekse Function Value’yu seçmeyi unutmayın.
Örneğin, count(//*[@class="örnek"]) sonucunda sayfada class’ı “örnek” olan elementlerin sayısına ulaşırsınız. Dolayısıyla bu XPath’i Screaming Frog’da Function Value şeklinde girmeniz gerekir.
Örnek Kullanım:
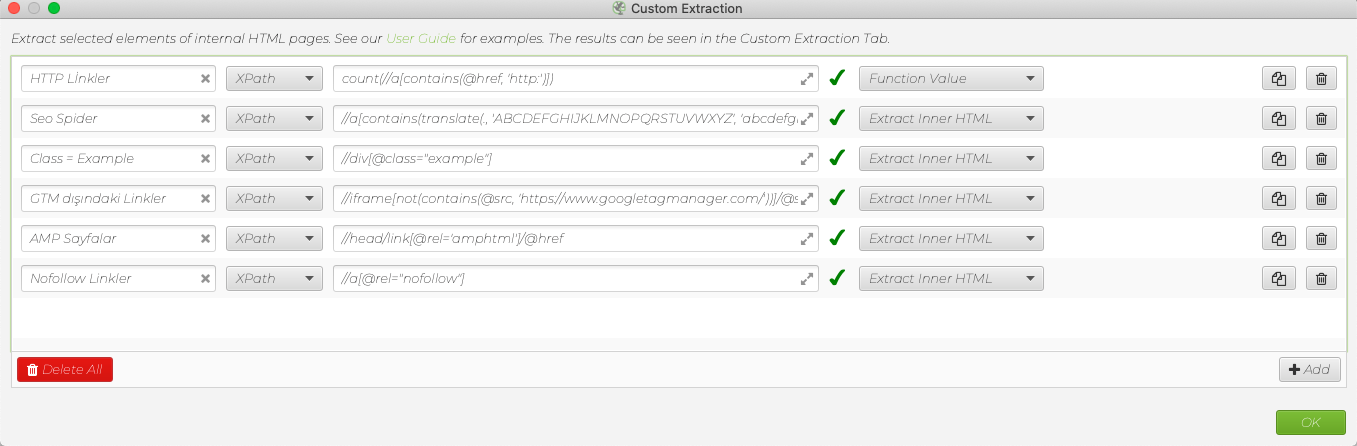
Sonuç
SEO analizlerinizi detaylı bir şekilde gerçekleştirmek, tabiri caizse ince iş yapmak istiyorsanız XPath bu konuda oldukça kullanışlı. Öğrenmesi ve yazması diğer dillere göre oldukça kolay olan XPath’i amacınıza yönelik kullanarak teknik veya içerik analizlerinizi detaylandırabilirsiniz. Yukarıda da belirttiğim gibi sayfa başına inceleme yapmaktansa Screaming Frog gibi bir crawler kullanarak analizlerinizi site geneline taşıyabilirsiniz.
Kaynaklar:
https://www.screamingfrog.co.uk/web-scraping/
https://www.screamingfrog.co.uk/how-to-scrape-google-search-features-using-xpath/
https://www.seerinteractive.com/blog/xpath-cheat-sheet-for-seo/
https://www.w3schools.com/xml/xpath_intro.asp
https://www.youtube.com/watch?v=anQF5_6oPMU






















