
Javascript SEO: What is SSR/CSR? Advantages and Disadvantages
Since you're reading this article, you probably know that websites are made up of the trio of HTML, CSS and JavaScript. And as you already know, along with the emerging technology, UI technologies have evolved, and websites have become virtually no different from mobile applications. We owe this development to the many modern UI libraries which AngularJS, VueJs, React JS are the frontrunners of.

Image source: https://www.deepcrawl.com/blog/webinars/webinar-recap-javascript-bartosz-goralewicz/
Advanced, mobile app-like websites are very nice and convenient for users, but it is not possible to say the same for search engines. Crawling and indexing websites where content is served with JavaScript have become quite complex processes for search engines. Let's take a closer look at this process.
1. What is JavaScript SEO?
JavaScript SEO is basically the entire work done for search engines to be able to smoothly crawl, index and rank websites where most of the content is served with JavaScript.
Modern UI libraries appear in websites in basically two distinct ways. This distinction stems from the rendering of HTML versions of websites on the browser or server side. This is the part which we as SEO experts have to take care of. Now let's get to know these two methods a little more closely:
1A. Client-side rendering (CSR)
In this technique, which has come into our lives with modern browsers, websites send very little HTML response to connection requests. This HTML response contains JavaScript codes that make up the content of the page. Unless these JavaScript codes are executed, the website is a blank page. The browser renders these JavaScript files, creates the content, and presents the web page to us.
1B. Server-side rendering (SSR)
It can basically be defined as doing the browser's work on the server. In connection requests to the server side, the server returns the entire page content as a readable HTML response. A readable content appears even when the JavaScript codes are not executed, but the page does not have the dynamics that the JavaScript codes provide. Then the Javascript codes start running and the page begins to make use of the advantages offered by modern UI libraries.
2. What Does Google Think About JavaScript?
Google hosts an annual event named I/O. They talk about the latest technologies and innovations they have developed at this event. Among these innovations, of course, is GoogleBot. GoogleBot used to work with Google Chrome v41 when crawling billions of pages on the internet. Google Chrome v41 had a lot of issues understanding and rendering modern JavaScript libraries. As a definitive solution to this situation, Google announced in I/O 2018 that they were working on GoogleBot to crawl the web pages with the current version of Google Chrome. They also announced that they have officially switched to v74, the current version of Chrome, in May 2019. (Click here to read the announcement.)
current version of GoogleBot can now understand the pages created with JavaScript. But here comes another problem. It is quite expensive to crawl JavaScript codes. Imagine for a moment that you're Google. Isn't it rather annoying, all the electricity spent and crawling efficiency reduced due to increasing processing volume? Therefore, these technological developments are not very economical for Google. Now let's see how Google handles this expense.
3. How Does Google Crawl Javascript Websites?
Google uses a method named two-wave indexing to crawl web pages created with JavaScript. So what is this method? Let's explain it briefly.
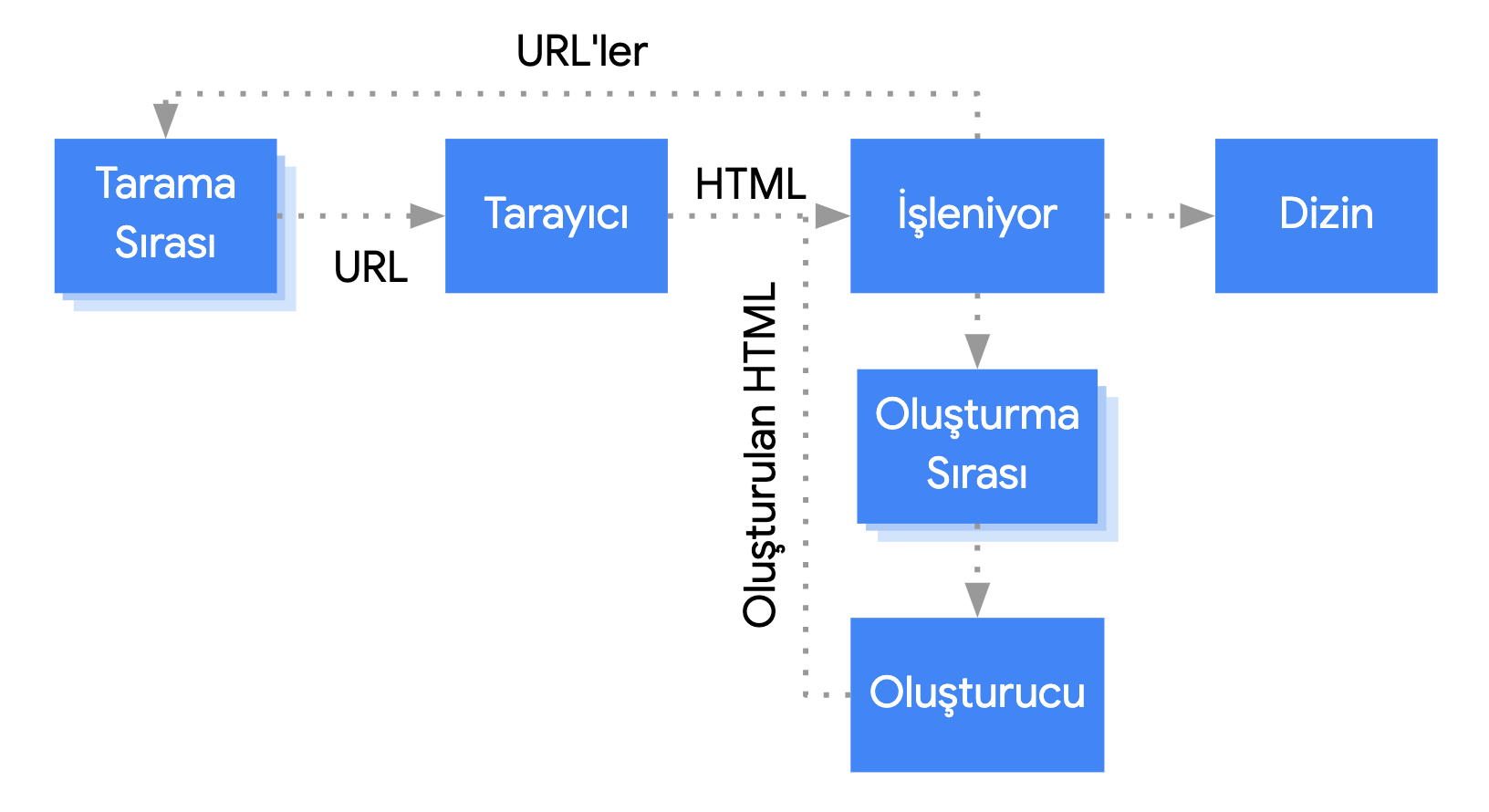
1.GoogleBot accesses the page and makes an HTML request for the first wave of indexing. It crawls, then indexes the HTML and CSS that are sent. At the same time, the links are added to the crawl queue and their status codes are added to the database.
This is the same crawling and indexing process that's used on normal web pages. As far as GoogleBot is able to see in your HTML response, it begins to understand your content and presents it to users.
2. GoogleBot adds your website to the rendering queue for the second wave of indexing and accesses it to crawl its JavaScript resources. This may take several hours, or even days, depending on how much Google values your website. It indexes a version of your content crawled with JavaScript. We would like to add that this process could take weeks if your website is new.
There's no problem if your content is not powered by JavaScript. Otherwise, it might take GoogleBot a long time to understand your content unless you make the right improvements.
4. Client-Side Rendering (CSR): A Look at CSR from an SEO Perspective
Let's first look at what happens in modern Javascript libraries when either GoogleBot or a regular user requests a page:
● The user or the search engine crawler makes a request to your address, https://example.com/a-sayfasi
● The server accepts the request and sends a response.
● The browser downloads the content along with the JS files.
● The browser executes the JS files in order to display the content.
● The content becomes available to be processed by users and bots.
Below you can see a sample CSR diagram prepared for ReactJS.
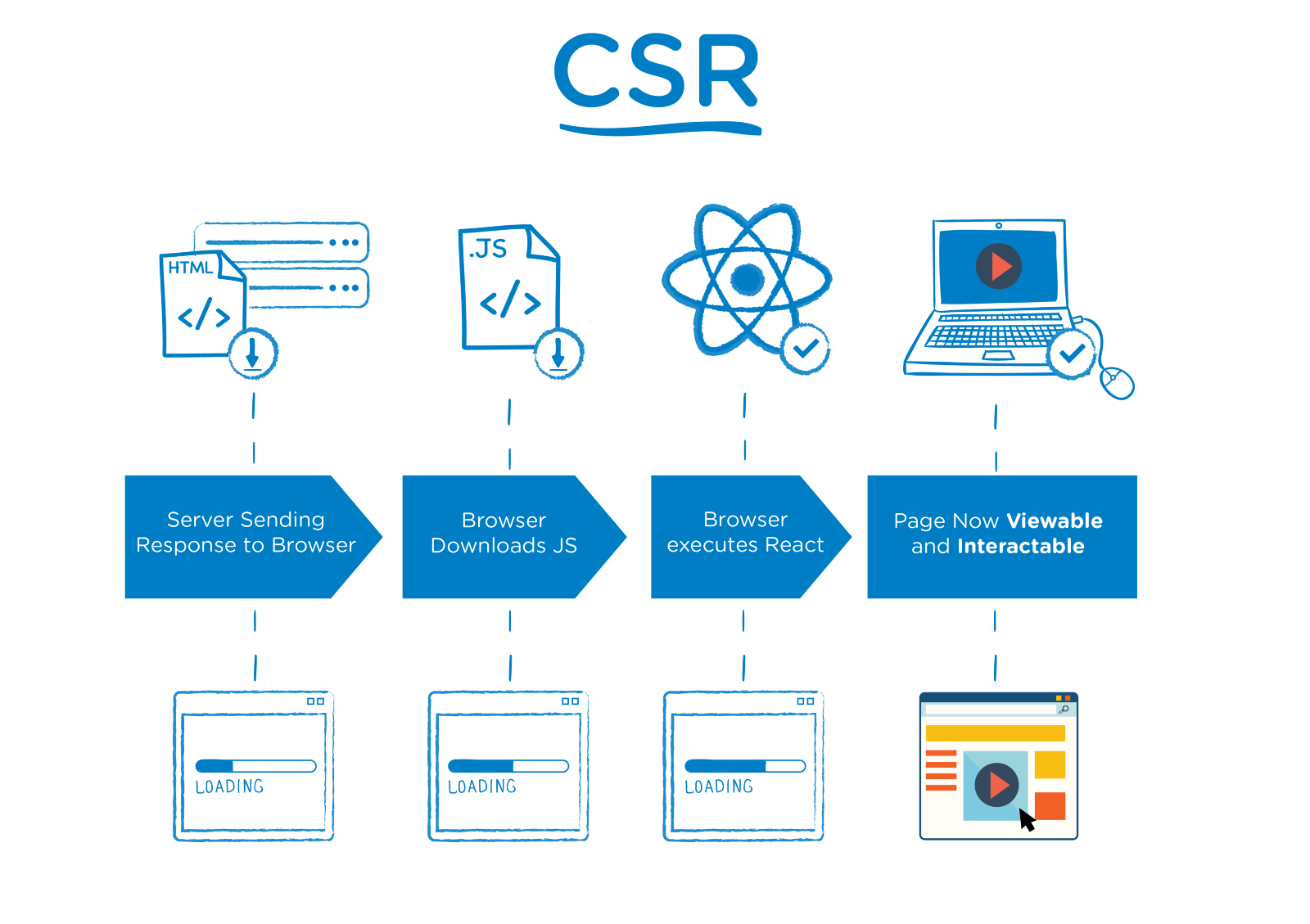
Image source https://medium.com/walmartlabs/the-benefits-of-server-side-rendering-over-client-side-rendering-5d07ff2cefe8
This process seems quite basic, however things get a little bit complicated at this point... As mentioned above, when we take into account that there are millions or even billions of pages that needs crawling, Google's limited (although we might assume they're unlimited) resources are insufficient in this regard.
At the same time, if we have to look from the users' perspective, the fact that the content is powered by JavaScript codes also brings along slowdowns independent from the server speed. Especially today, when the mobile revolution is taking place, hundreds of different devices have different levels of processing power. If your website is accessed via a phone with low processing power, it takes longer to interact with your website regardless of the user's internet speed. And when the waiting time is too long, it leads users to exit your page.
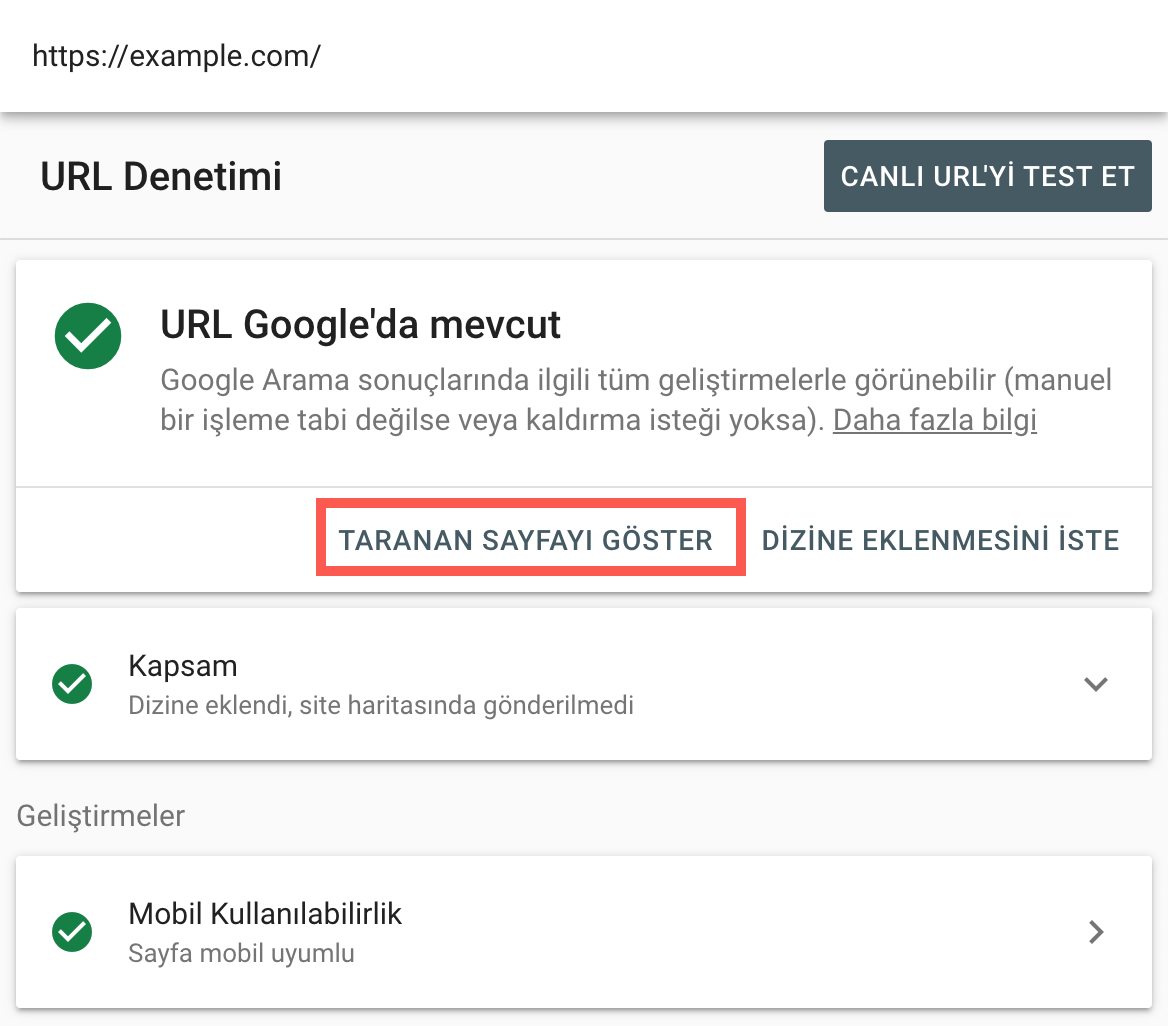
In short, the page that you have created with the latest technologies and utmost care might seem like a blank page to Google. If you have a website powered by modern JavaScript libraries, go to Google Search Console and regularly check how Google sees your website by pressing the button "View a rendered version of the page" in the URL Inspection tool. If your webpage is still not in the Google index, you can go with a Live URL test.
4A. Dynamic Rendering:
Dynamic rendering is basically a method used to make a client-side rendered website SEO compliant. The main difference lies in serving GoogleBot and users different versions of the HTML content.
When your server receives a request, it determines whether the request was made by GoogleBot or a user. If it's GoogleBot, it receives a server-rendered HTML response . Other users continue to access your client-rendered website.
If you want detailed information about this topic, I recommend What is Dynamic Rendering and What Are Its Test Stages?, an article written by Samet Özsüleyman, our friend from the ZEO team.
5. Server-side rendering (SSR): A Look at SSR from an SEO Perspective
Let's first look at what happens in modern Javascript libraries when either GoogleBot or a regular user makes a request, as we did above. This way, we will be able to understand it better.
● The user or the search engine crawler makes a request to your address, https://example.com/a-sayfasi
● The server accepts the request, renders the entire HTML, and sends a response.
● The browser downloads the rendered HTML along with the JS files.
● The content becomes available to be processed by users and bots.
● The browser executes the JS files in order to make use of the advantages of the modern UI libraries.
● The website becomes available for interaction.
Below you can see a sample SSR diagram prepared for ReactJS.
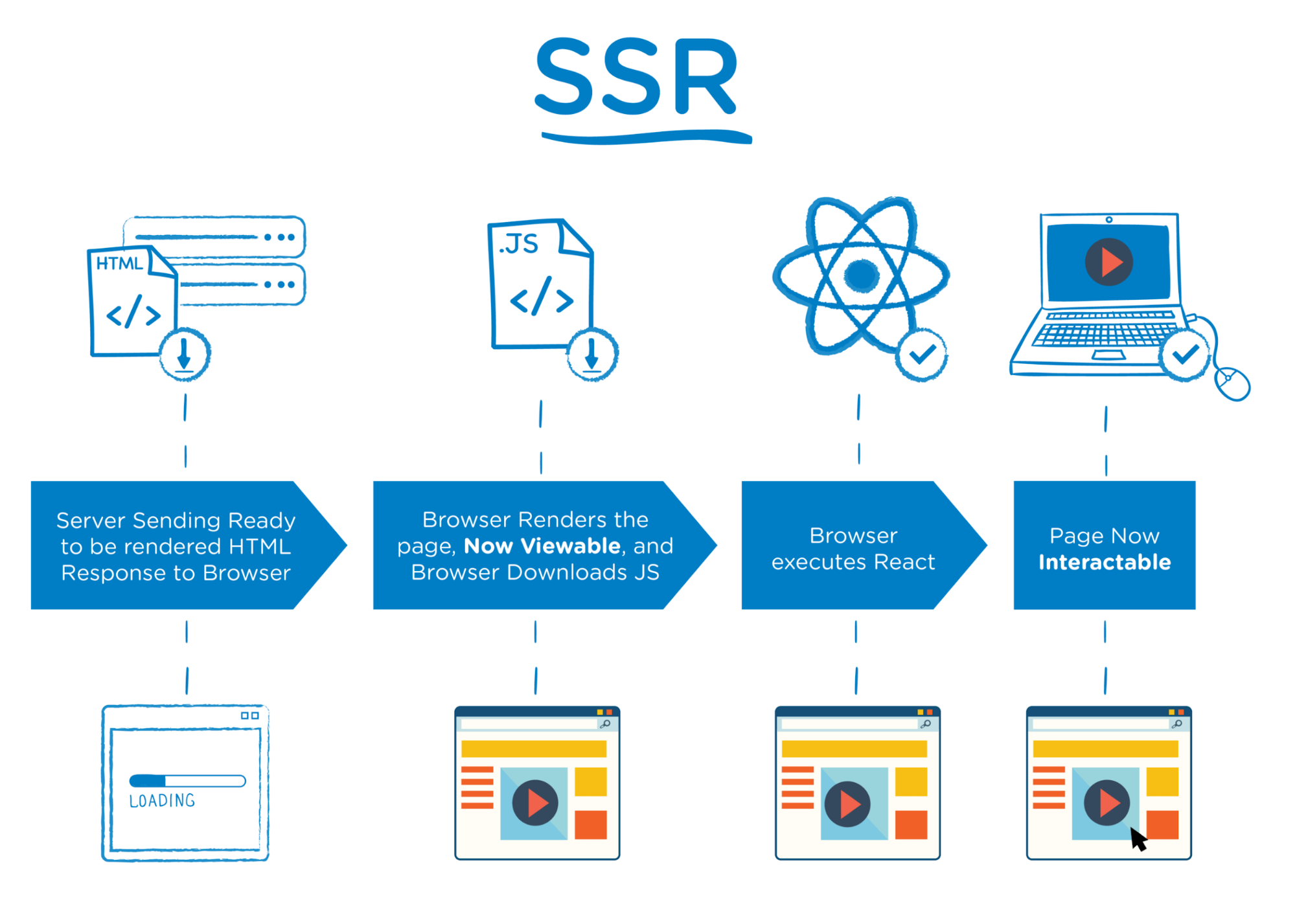
Image source https://medium.com/walmartlabs/the-benefits-of-server-side-rendering-over-client-side-rendering-5d07ff2cefe8
SSR is a structure supported by Google. You can click here to read the relevant documentation.
We have some basic knowledge of CSR. It requires extra processing power and crawling cost. It's completely different when it comes to SSR. Google doesn't have to download and render JavaScript files or make any extra effort to browse your content. All your content already comes in an indexable way in the HTML response. So you don't need technologies such as two-wave indexing or dynamic rendering for your content to gain recognition and be ranked in Google.
Conclusion
Websites powered by modern UI libraries can be created with two methods, CSR and SSR. And Google bots, our main source of traffic, don't really like CSR out of the two and can't promise to recognize it properly. In this case, the answer becomes more clear; if you already have a website made with CSR and it has indexing issues, dynamic rendering seems to be optimal for you. But if you're going to start coding from scratch, we think SSR makes more sense.
As you can see in the table below, while some libraries have native support for SSR integration, additional solutions may be needed for other libraries. The main point to note here is that there are SSR integrations that work very well with the three libraries listed below, which constitute the majority of the market.
Library SSR Solution
React Next.js, Gatsby
Angular Angular Universal
Vue.js Nuxt.js
We're sure that Google follows the development process of UI technologies more closely than we do. Therefore, Google will be able to work with JavaScript more efficiently over time, increasing the speed of crawling and indexing. But until then, if we want to use the benefits of modern UI libraries and at the same time avoid any disadvantages in terms of SEO, we have to strictly follow the developments.
Sources:
https://developers.google.com/search/docs/guides/javascript-seo-basics
https://developers.google.com/web/updates/2019/02/rendering-on-the-web
https://www.deepcrawl.com/blog/webinars/webinar-recap-javascript-bartosz-goralewicz/
























